6 识别语言
现在,我们是时候再让机器做点真东西了。
比如:识别语言
什么是语言?这就要从语言学的一个子领域语义学(semantics) 开始说起。

其中一个观点就是:词语的意义来自于它的用法。换句话说,如果想要了解一个词的意思,只要看它怎么用就好了。
比如说我们想了解赛博朋克这个词,那么只需要去百科里搜索,然后看看它周围有什么词。黑客、科幻、未来这些词的出现频率都很高,这已经和自然语言处理(NLP,Natural Language Processing) 的研究方法很像了。

现在,机器理解语言的一种常见方式就是建立遮蔽语言模型(MLM,Masked Language Model) ,机器会先随意遮掉一个句子中的词,然后看上下文反推出这个被遮掉的词是什么。这样,每一个词的意思都和他周围的词相关。换句话说,如果机器能做完形填空,它在某种程度上就理解了字词的意思。
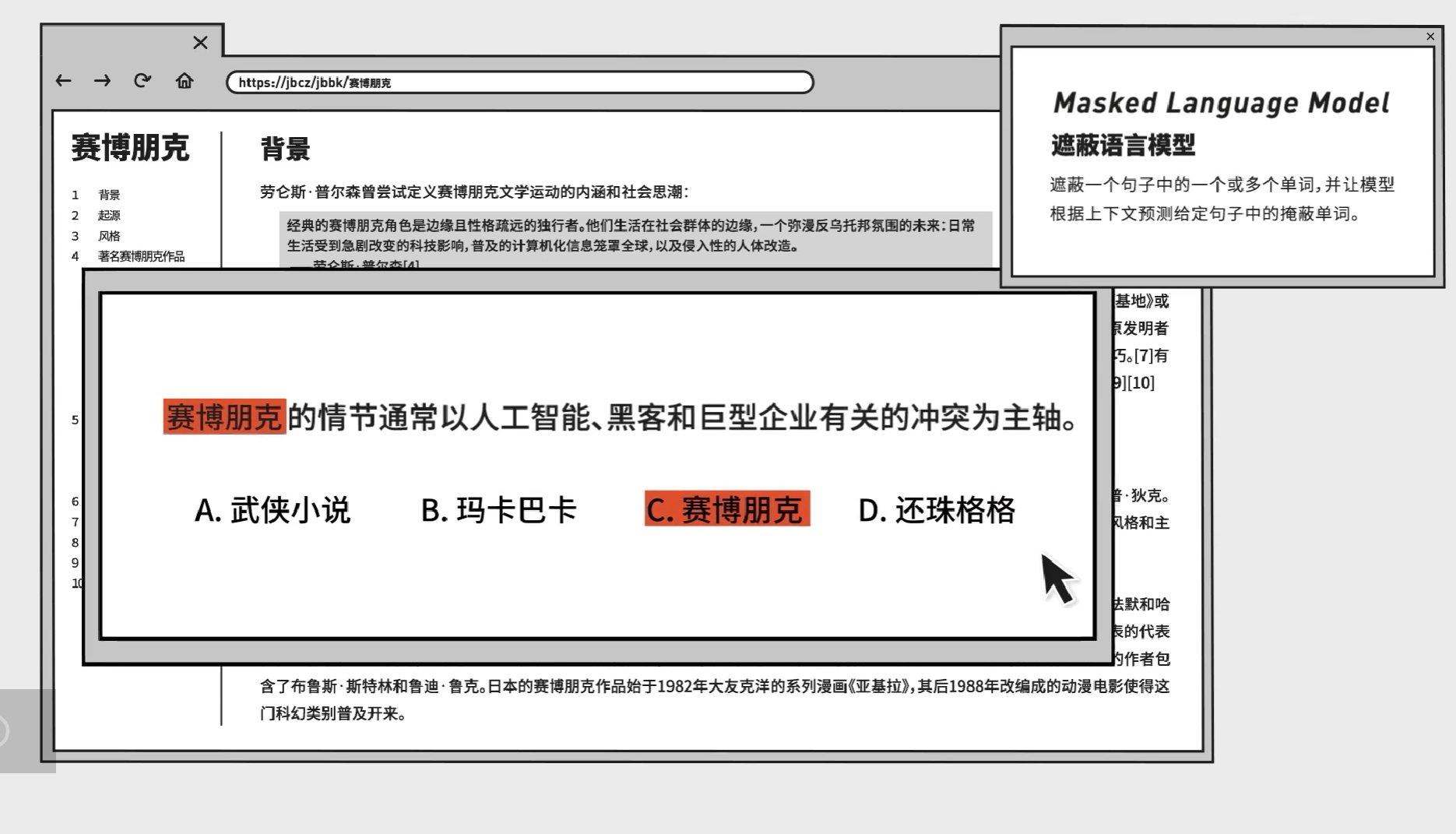
如何让机器做完型填空呢?还是要靠神经网络。先看输出的部分。在机器的眼中完形填空还是一种多分类问题。机器做的就是选出正确的选项,但其实并没有人给它设计选项,它的选项就是所有可能的字,这个选项非常多,以常用3500汉字为例,如果以词为单位,那么机器就是要分类几百万种代表词汇的点。
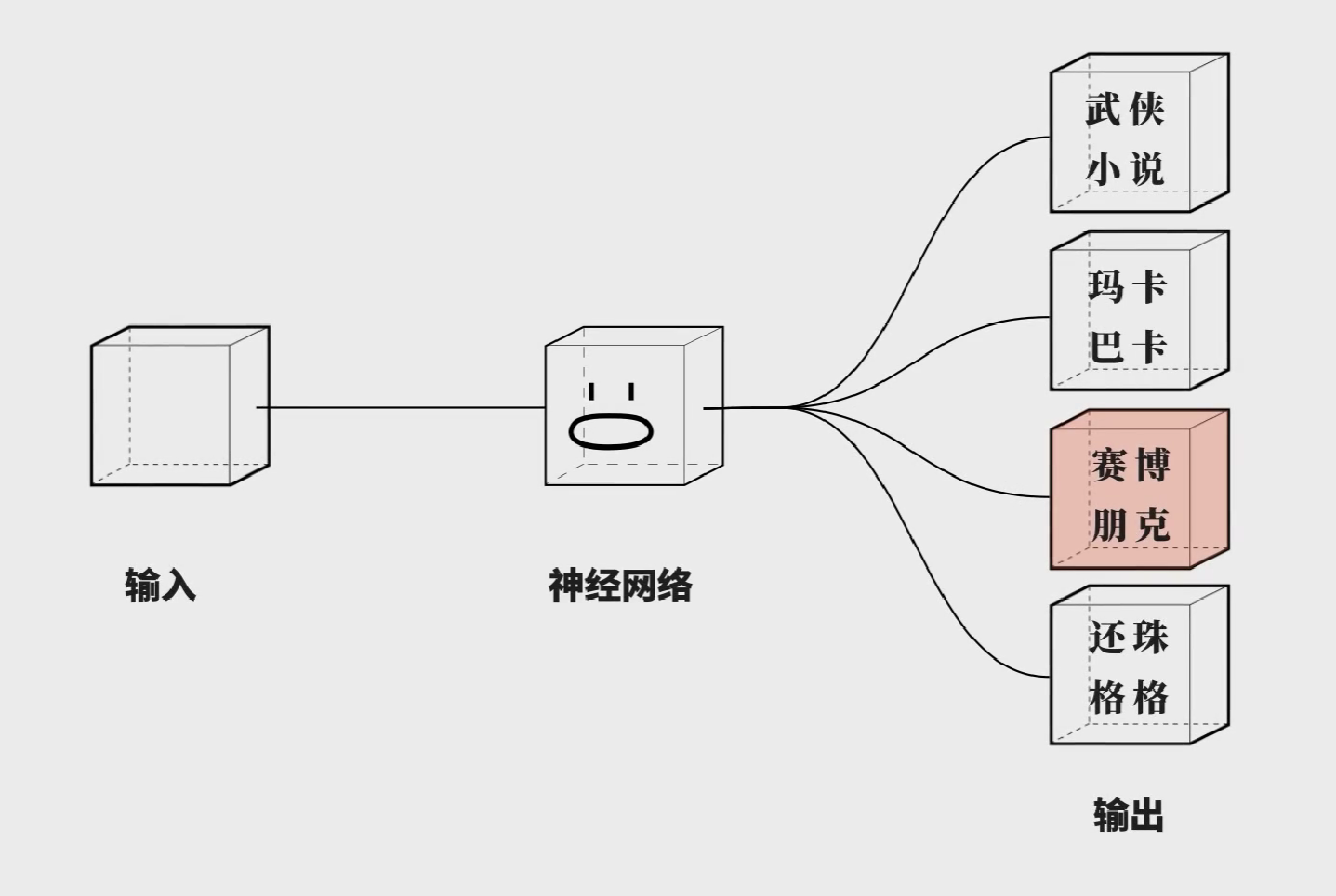
了解了输出之后,我们还要考虑输入,我们之前的网络结构都是遇到一个输入,突出一个输出,这个输出只和当前的输入有关,次序不重要。然而,语言是存在次序的,因此我们需要一个神经网络来处理有顺序的数据。隆重介绍:循环神经网络(CNN,Recurrent Netural Network)同样的输入数据顺序不同,经过循环网络之后的结果也不同。
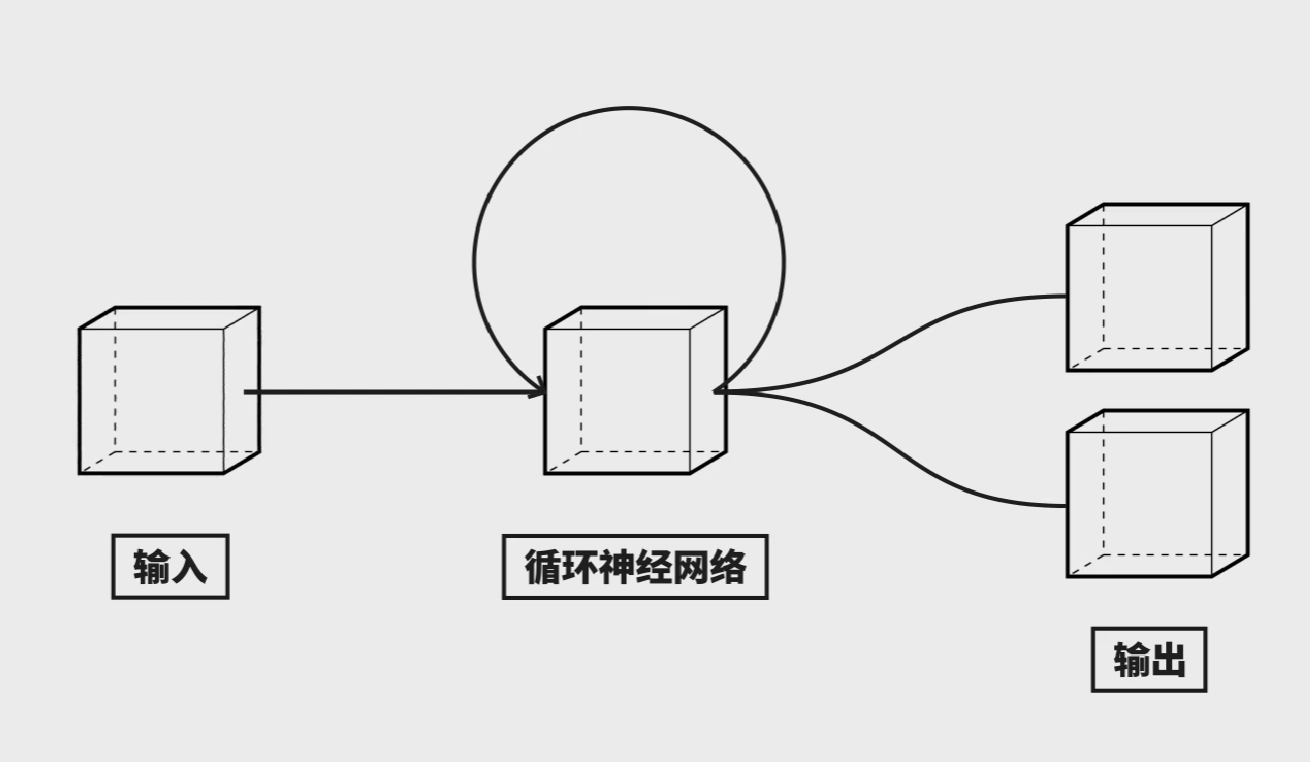
让我们直接算一算,看看他是如何做到的。
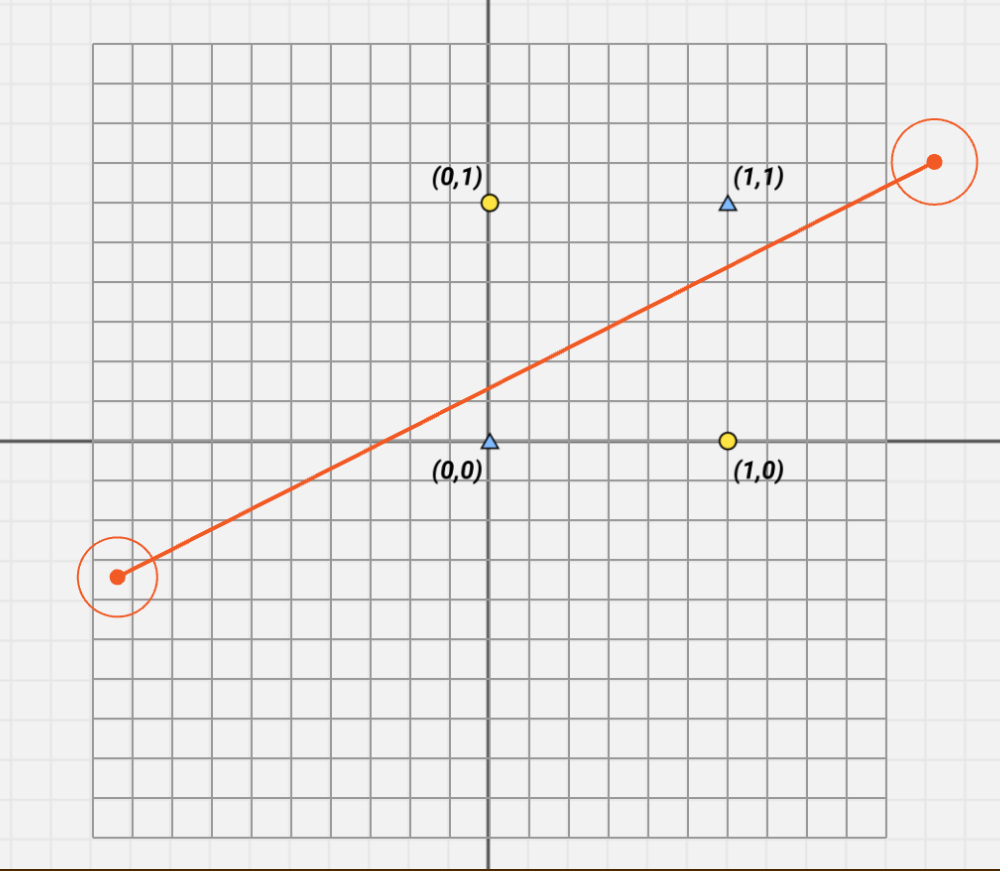
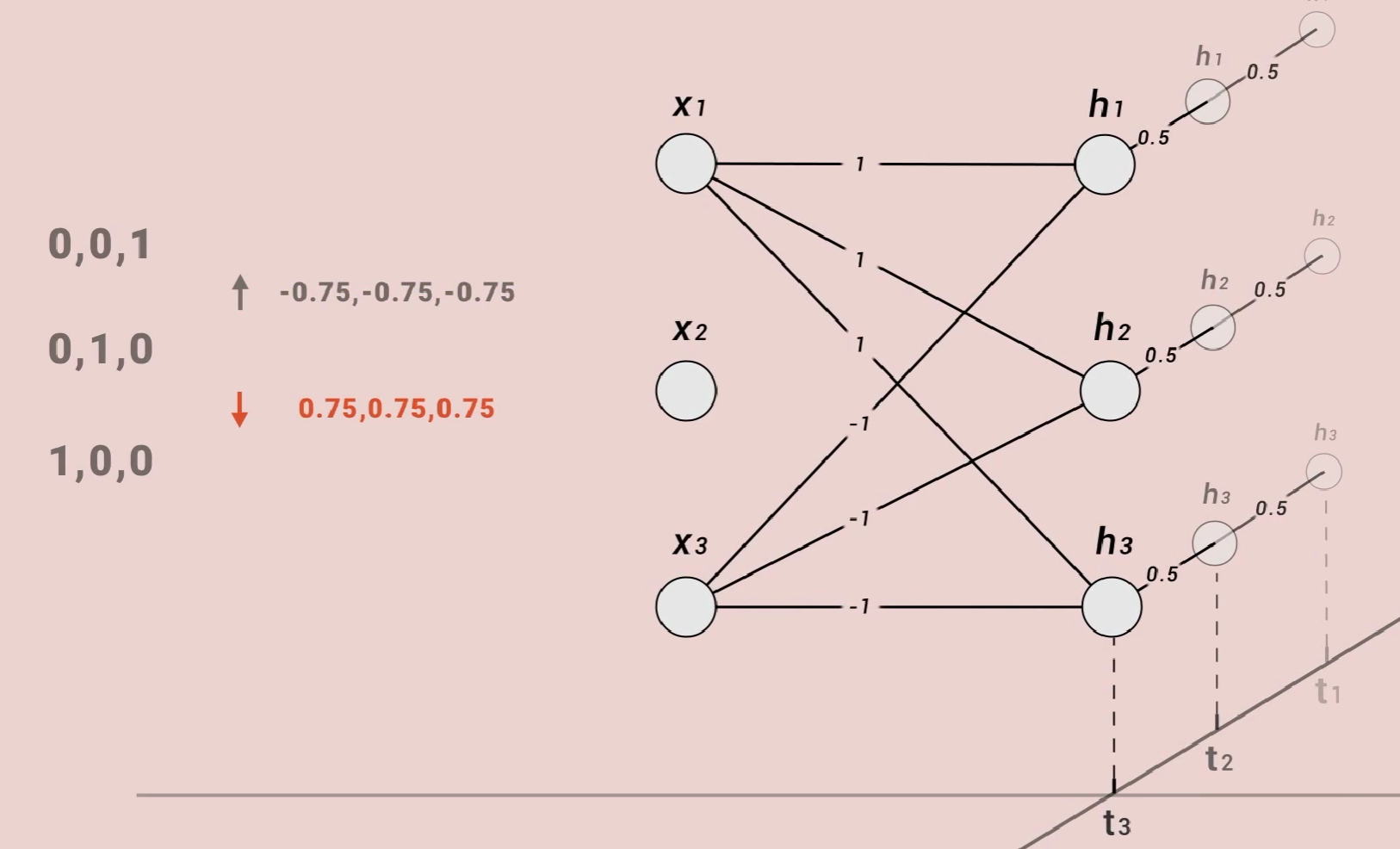
这是一个简单的循环神经网络,三维输入,三维输出。特别之处是,这一层神经元有记忆,每次运算这层神经元的值都会被存一份,然后以这种连接方式参与下次计算。我们把权重为零的线隐藏。为了计算方便,我们把其他权重设成这样。我们也可以把权重为零的线隐藏,且暂时都没有激活函数。

现在我们把(0,0,1)(0,1,0)(1,0,0)按顺序输入,当输入第二个数据时,需要同时考虑输入数据和上一次的输入数据。
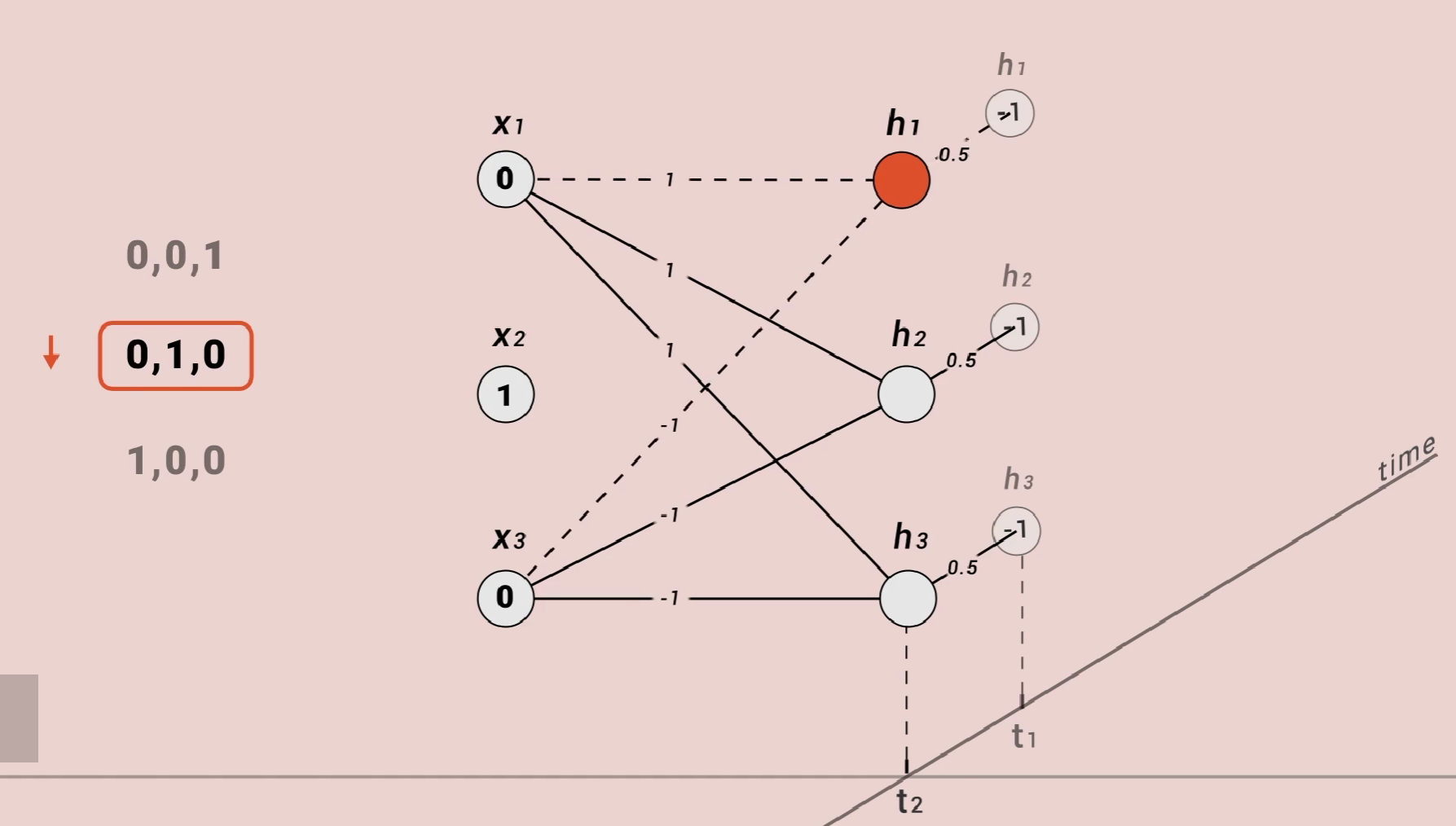
输入第三个数据时同理,最终网络的输出值就是(0.75,0.75,0.75)。但是如果我们把三个数据反向输入网络,所得到的结果也会不同,可以得到(-0.75,-0.75,-0.75)
现在回到完形填空。因为每一次运算都会用到前一个输入的隐藏信息,你可以把它抽象的理解为代表上文语境的向量。这个网络还可以反着学,如果我们要预测的是第一个字,就可以把句子倒着输入网络,让他获取下文信息。
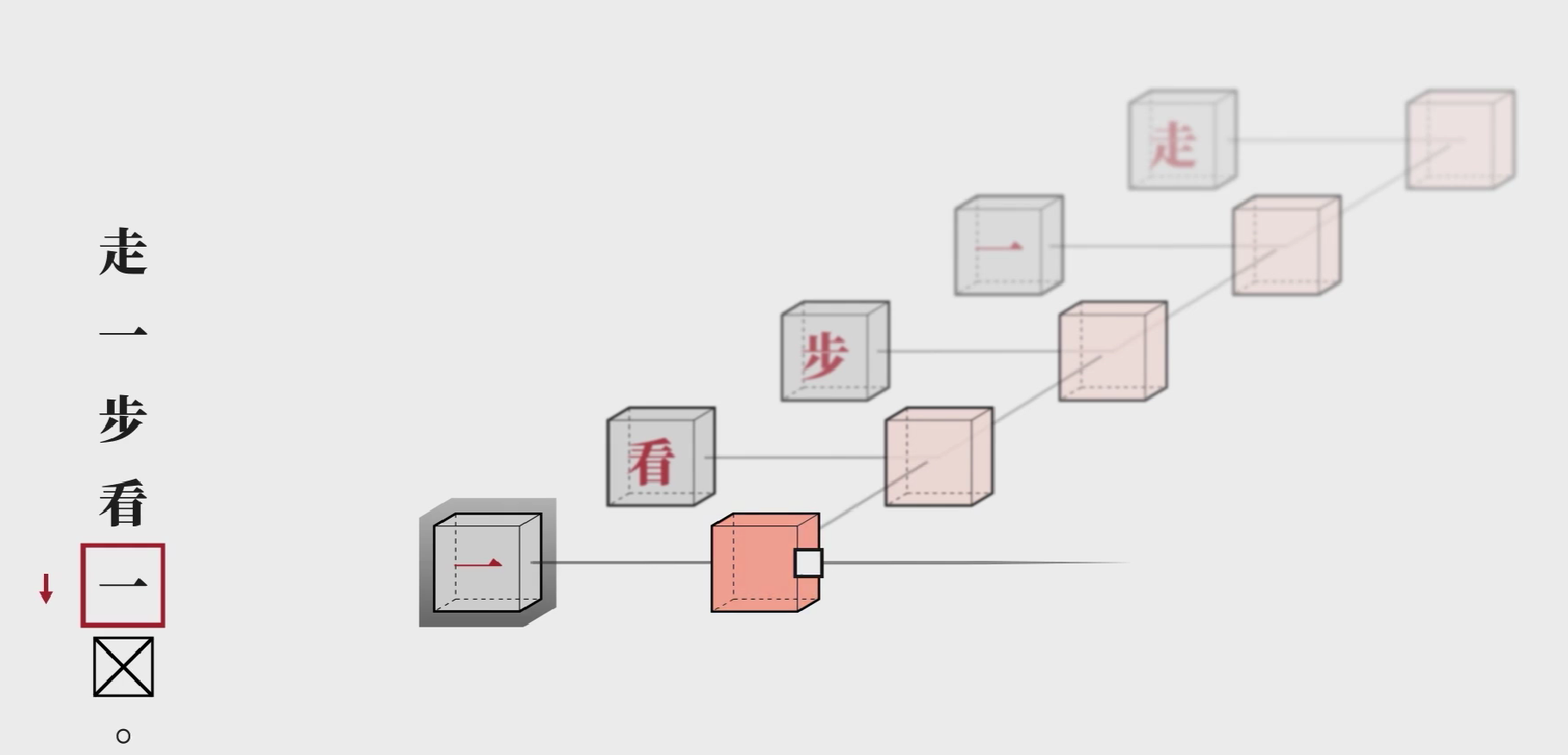
如果抠掉中间的字,这时候我们就需要双向循环神经网络(BRNN,Bidirectional Recurrent Netural Network) ,让正向和反向的神经网络输出合起来,获得这个y,它就包含了前后所有的信息。接下来实际我们要做的就是在后面接一个全链接层,完成多分类任务。

这是我们熟悉的任务,根据预测结果和真实值的误差,我们可以用梯度下降和反向传播调整神经元的权重。只要有足够多的语料,理论上机器就能自动完成完形填空,形成对每一个字的理解了。
注意,上面描述的循环神经网络是一个极端的简化版本,现在这种简单的单元已经不会在实战中使用了,其中一个原因是它很容易忘掉最开始的输入,比如在第五步时,第一步的输入不是当前输出的1/5,随着句子的加长,影响指数级下降。
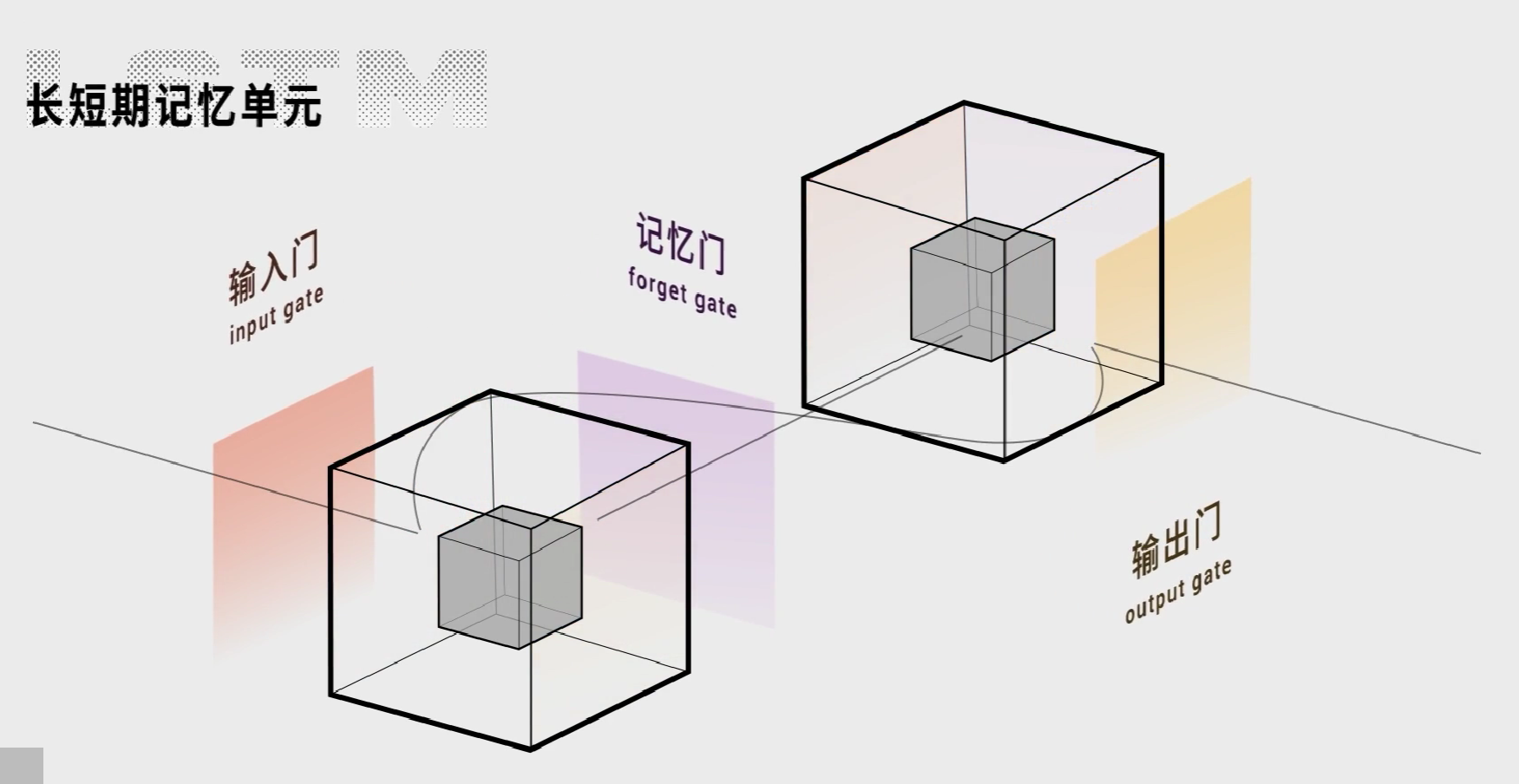
因此出现了许多RNN的强化版,比如长短期记忆网络(LSTM,Long Short Term),它在RNN的基础上加了三个门,从而让记忆留的更久。
这个网络还可以加深,如果正向、反向的网络同时叠上两层,这就预训练模型ELMo的结构。
除此以外,还有BERT,GPT-2等其他运行的模型,其中有一些甚至已经抛弃了循环神经网络。
这个会做完形填空的神经网络就是现在计算机语言的第一步,现在经过预训练模型之后的这个向量就包含了上下文信息,我们也可以抽象的理解为他在提取词语的特征,这个特征是通用的,不管是探测句子,情感,翻译出去文章简介,还是生成文章,我们都会首先揭露这个模型。

这时机器算是理解语言了吗?
其实,它做的,还只是分类。
 wechat
wechat alipay
alipay