5 识别图像
现在,我们的神经网络已经可以区分出图像上不同的点了,是时候让它做点真东西了。
比如:破解图片验证码。
验证码的英文是CAPTCHA,即:Completely Automated Public Turing test to tell Computers and Humans Apart,全自动区分计算机和人类的公开图灵测试。
验证码,这一对于人类来说可以简单完成的任务,对于机器来说却十分复杂。机器擅长的是有明确规则的事物,但是我们却无法总结出几条确定的规则告诉机器验证码该怎么填。
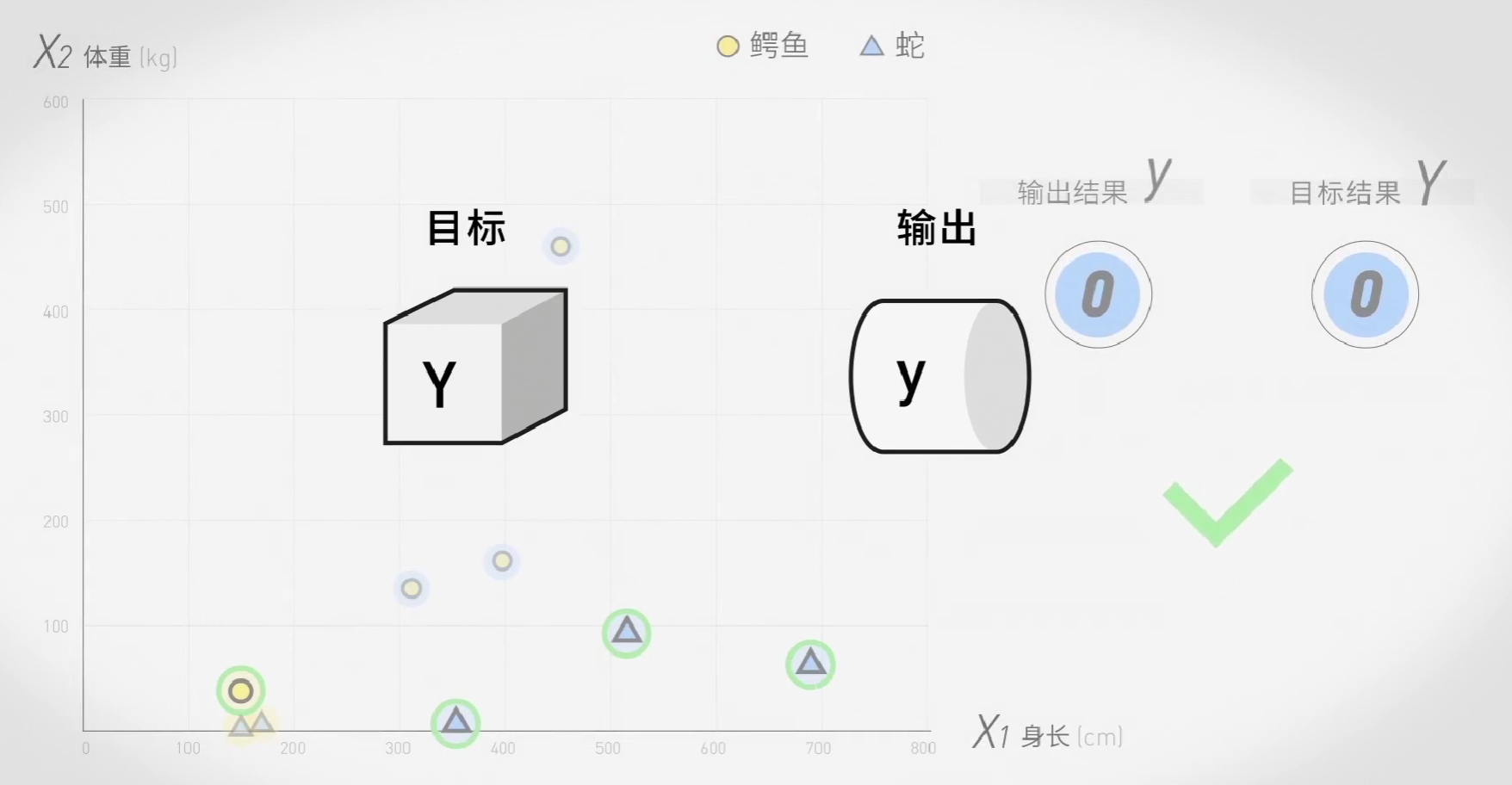
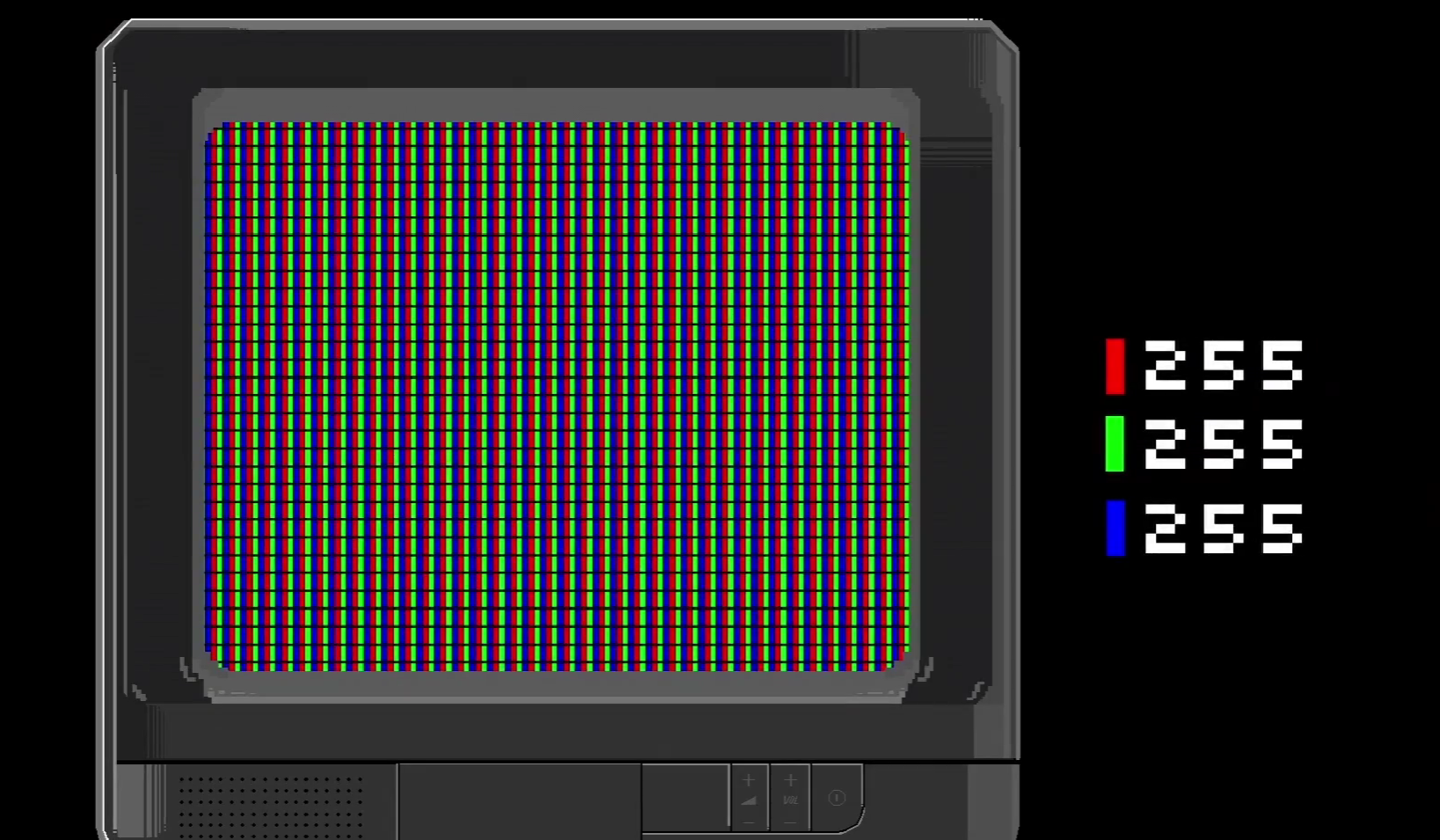
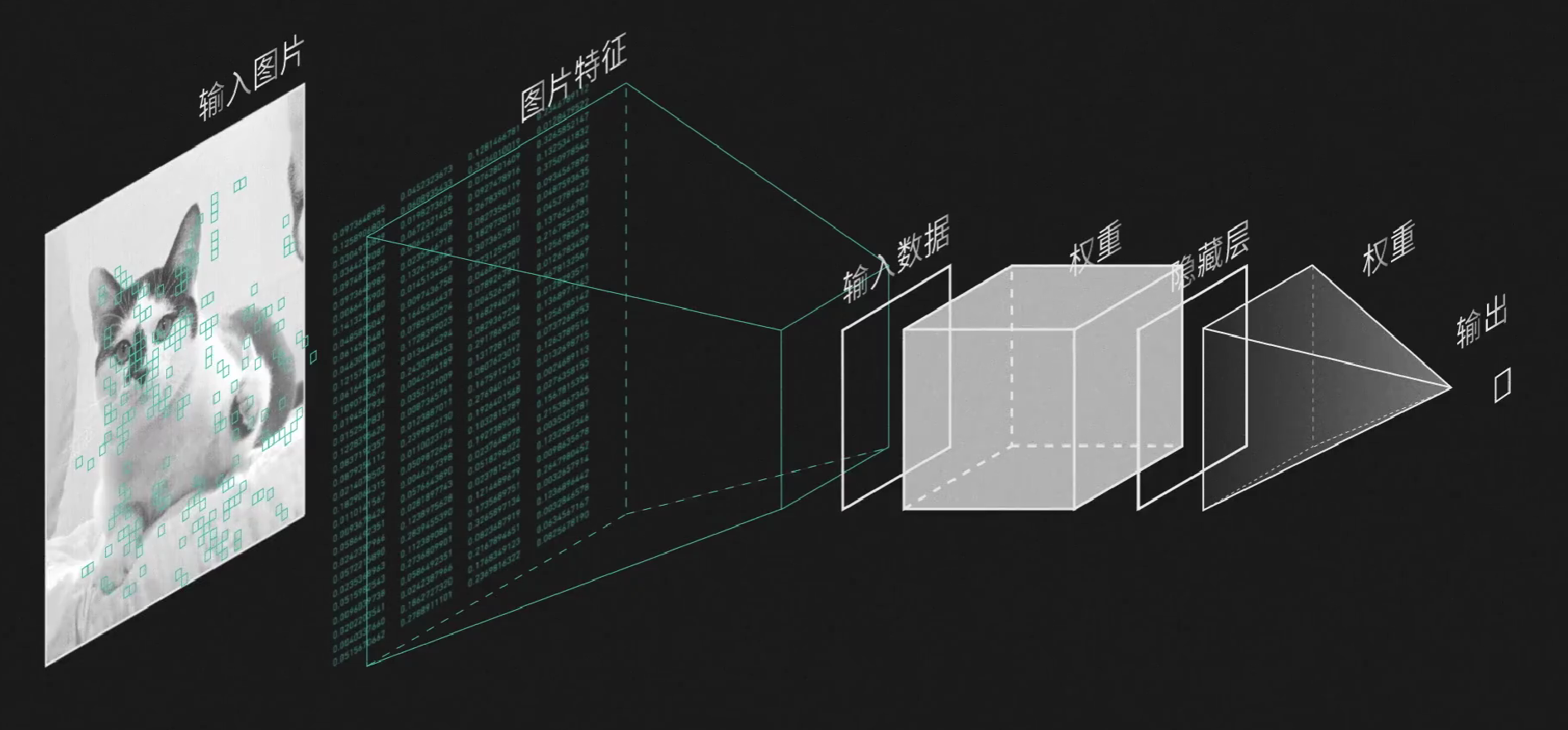
但是,其实最开始借助于MNIST数据库,机器就已经可以识别简单的数字了。它分为三步:输入图片->转化为数字->用神经网络分类。

但如果继续用这个单层感知器,它的效率就有点低了。比如说处理一张$300\times 300$的图片,输入向量就相当于有90000($9\times10^4$)维,要和$9\times10^4$个权重相乘并且分类,而且我们很难线性分开,一般中间还要加隐藏层,假设隐藏层神经元个数和输入层一样多,每一个隐藏层神经元都会连$9\times10^4$个参数,那么光是中间层就有$(9\times10^4)\times (9\times10^4)=8.1\times 10^9$个权重,需要通过反向传播来调整。

但如果我们可以事先提取图片的特征,把它从几万个像素数据简化成数百个数字,然后再用之前的神经网络分类,这样分类时的运算量就会小很多,而提取特征就由卷积神经网络(Convolutional Neural Network)来实现。
这就是一个典型的卷积神经网络结构,它可以粗略的分为两部分:提取特征(Feature Learning) 和 分类(Classification)。
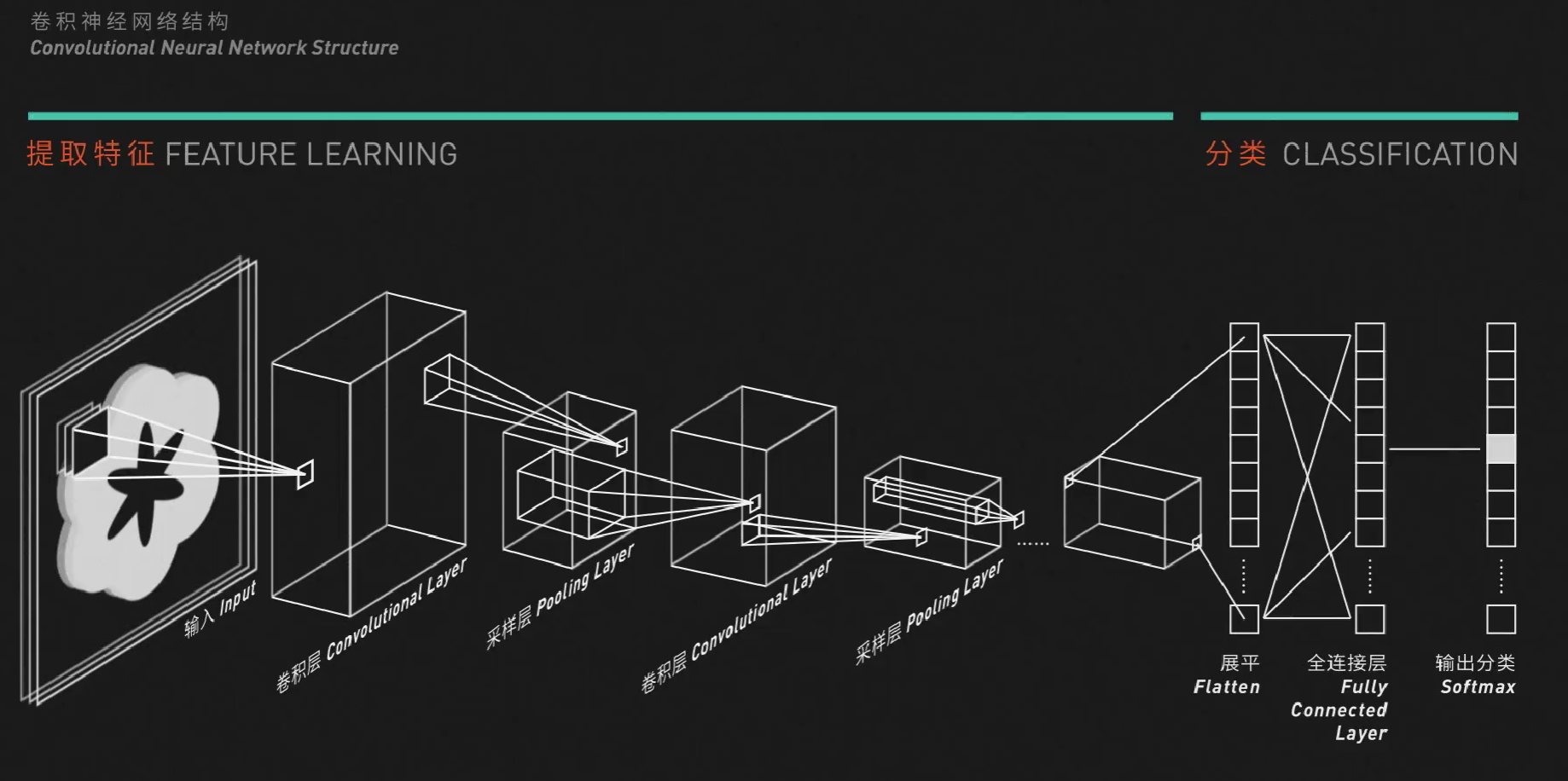
特别之处在于前半部分:多出了卷积层(Convolutional Layer) 和 采样层(Pooling Layer)。多个卷积层和采样层叠加,就能实现数据的特征提取。
隆重介绍:卷积。它是一种特殊的乘法。首先以一维卷积为例:第一个元素是原始数据,第二个元素则是卷积核(Convolution Kernel)。它的运算方法很简单:让前三个数据与卷积核对应位置的数据相乘,然后相加,再把结果填回中间的格子。
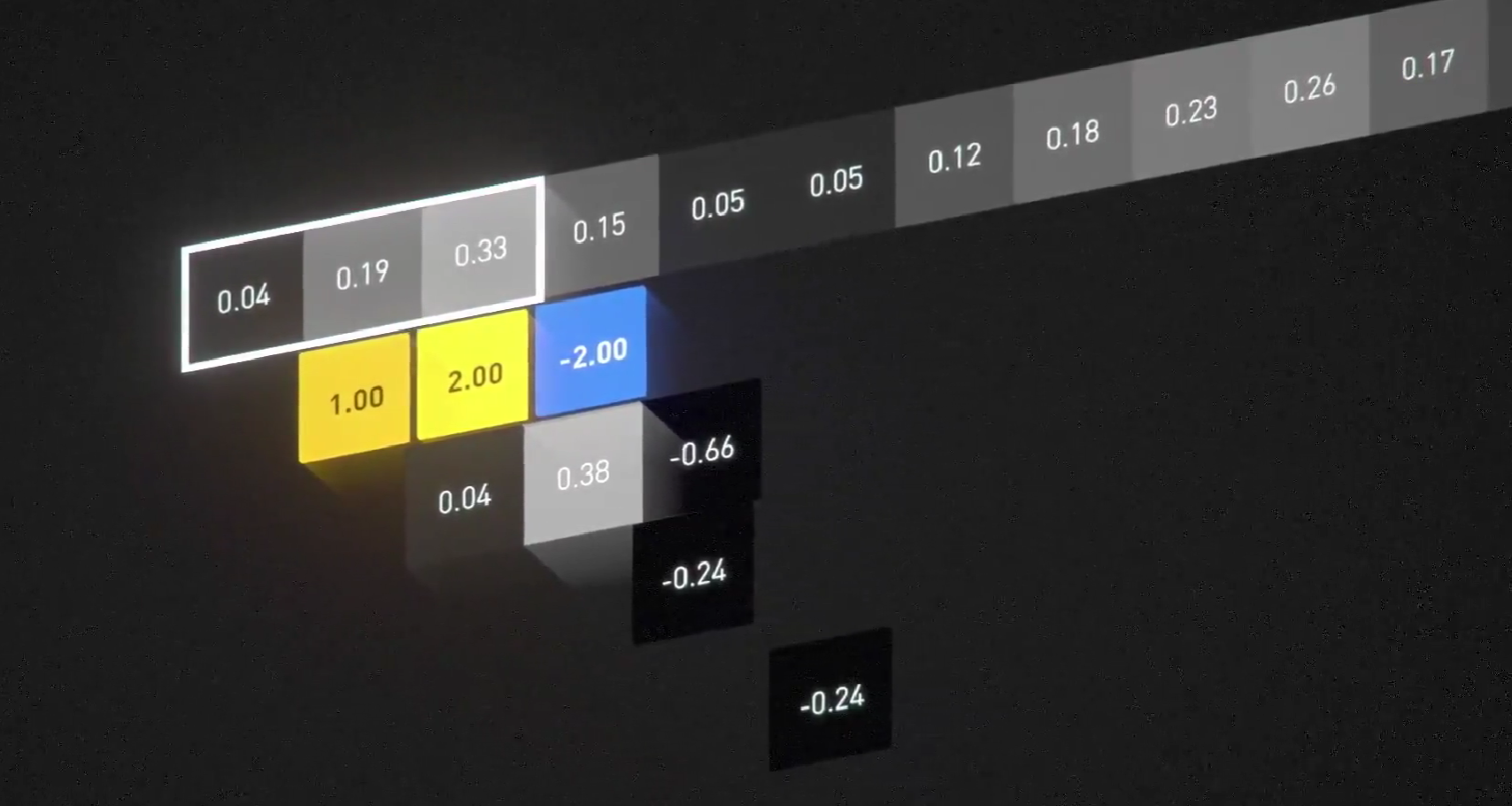
算完一个以后,我们让卷积核向右滑动,以同样的方法填下一个数据。

卷积运算的输入也可以是二维的,比如输入是一个$53\times 53$的矩阵,卷积核是一个$3\times 3$的矩阵,那么运算规则就是对应位置的数据相乘再相加。

这样,我们就能获得二维数据。

而采样数据更好计算,最大采样就是取原始数据的最大值,和刚刚一样,让采样核划过整个屏幕我们就得到了精简之后的数据。除此以外还有平均采样,就是取每九格中的平均值,计算方法类似。

算法很简单,但是为什么卷积和采样是在提取特征呢?
比如这个核,就是在提取上边缘特征:


在扫过上边缘区域是,黄色区域对应的图像灰度大于蓝色区域的图像灰度,输出为正数,提取出白色。

在纯色区域,卷积结果正负相抵,提取出黑色。

所以我们就提取出了图片的上边缘特征:

同理,如果我们使用$\left[ \begin{matrix} 1.00&1.00&1.00\ 0.00 & 0.00& 0.00 \ -1.00 & -1.00 & -1.00 \end{matrix} \right]$作为卷积核,就可以提取图片的下边缘特征:

同理,这里给出提取图像左边缘与右边缘的卷积核:
左边缘:
右边缘:
这就是一次卷积和采样。它做的就是寻找图像上卷积核所对应的特征,并把它精简成特征图。我们还可以在一个图上用上多个卷积核,得到多个特征图,在多个简单特征图上做卷积,再相加,相当于在简单特征中提取复杂特征。
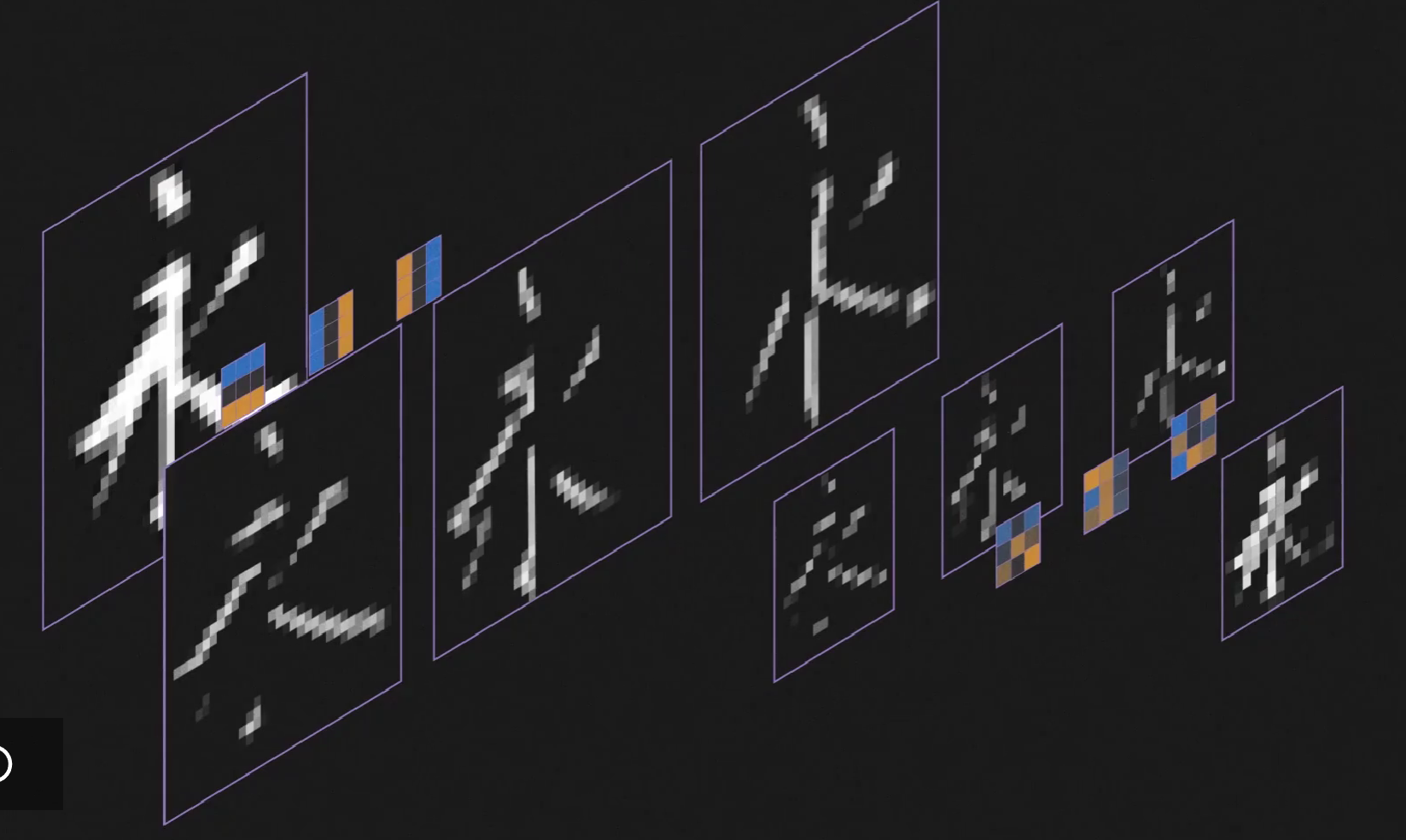
在卷积神经网络中,我们可以加入任意多的卷积层和采样层,以识别更复杂的特征。

其实,动物大脑识别图像的过程与之类似:
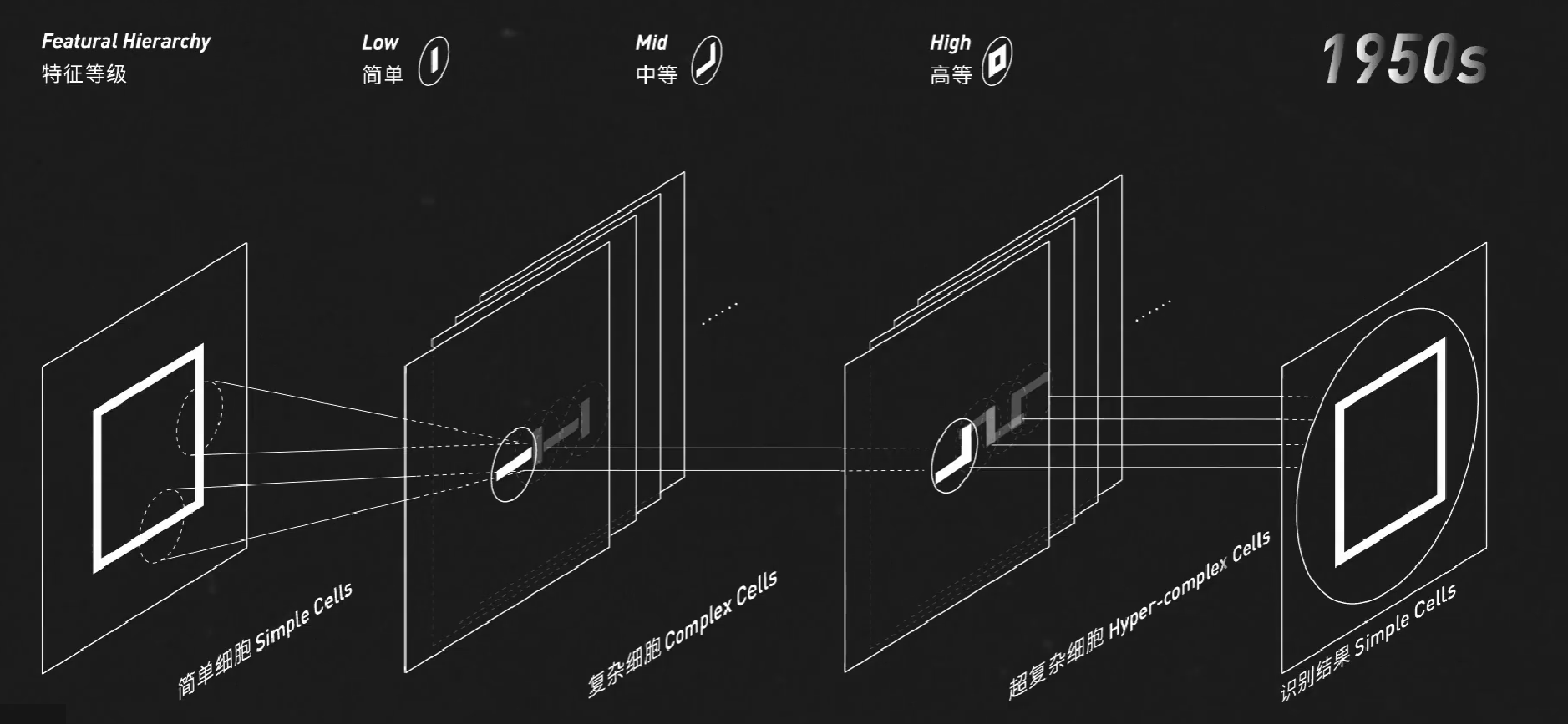
这给了三十年后的日本科学家福岛邦彦(Kunihiko Fukushima)极大的启发。他模仿这个分层级的结构造出了人工大脑。他能在前层识别A的尖、角、连接处等特征,在后层进行组合,最后识别字母A。
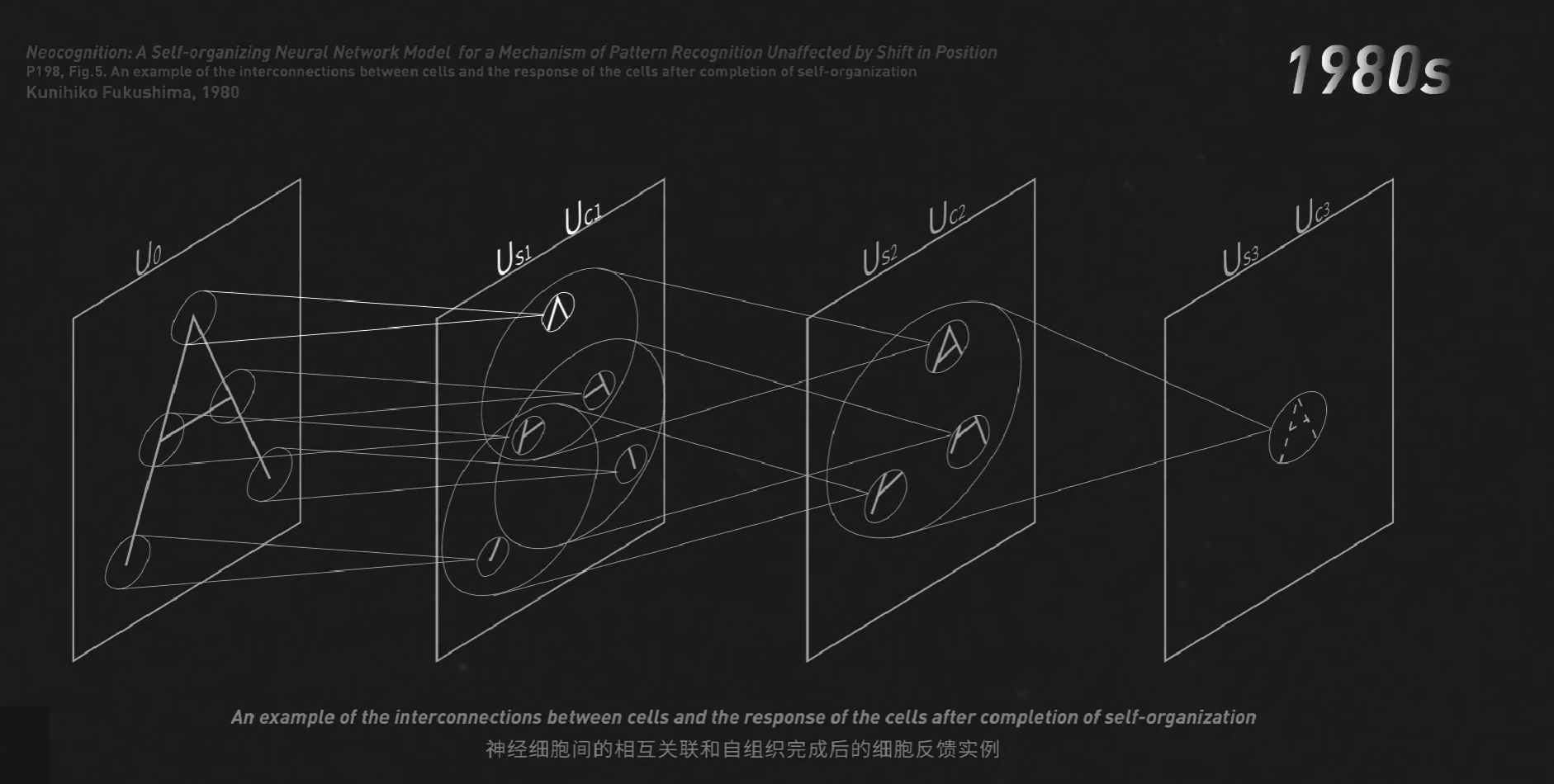
这里用到的算法就是卷积和采样,我们还学会了在每一次卷积后加一层ReLU激活函数来适应复杂的非线性问题。

这就是机器识别图像的过程,它本质上仍然是我们熟悉的多分类问题。
 wechat
wechat alipay
alipay