
软件工程课程设计 & 理论课实验报告
1-6为课程设计报告,7为理论课报告。
如果帮助到了你,可以进Github页面点个Star噢!
报告仓库:dekrt/Reports: HUST SSE Courses Reports | 华科软件学院课程报告 (github.com)
1. 项目概述
1.1 项目基本介绍
TransWe
Translate WeChat Mini Program
简体中文 | English📱 UI界面
![]()
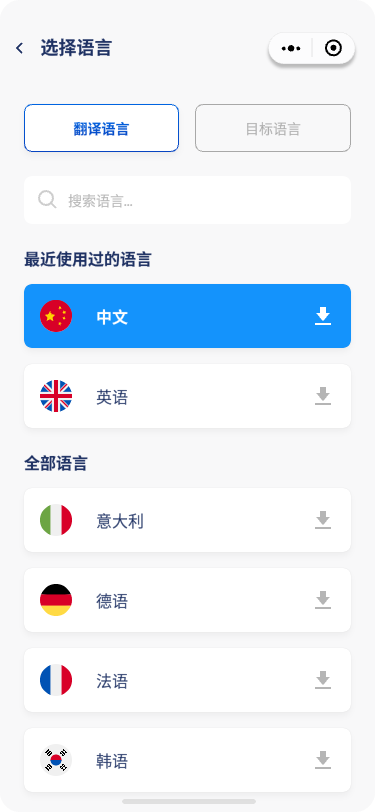
![]()
![]()
![]()
📖 项目介绍
TransWe意为Translation+Wechat,是一个功能强大的机器翻译微信小程序,它能够通过后台机器翻译服务快速、准确地翻译各种语言。它还支持第三方OCR、语音识别和语音合成集成,为用户提供更便捷、高效的翻译服务。
TransWe功能包括:
- 机器翻译:TransWe使用后台机器翻译服务,支持多种语言翻译,包括英语、中文、法语、德语、日语、韩语等,能够准确、快速地翻译用户的文本。
- OCR识别:TransWe支持第三方OCR识别,用户只需要上传图片或拍摄照片,就能将图片中的文字转换为文本进行翻译。
- 语音识别:TransWe支持第三方语音识别,用户只需要录制音频,就能将音频中的语音转换为文本进行翻译。
- 语音合成:TransWe支持第三方语音合成,用户能够将翻译结果通过语音合成功能转换为语音输出,提高用户的交互体验。
TransWe使用简单,功能强大,只需选择需要翻译的语言,输入要翻译的文本,点击“翻译”按钮,TransWe将自动完成翻译,如果需要使用OCR识别、语音识别或语音合成功能,可以选择相应功能按钮,按照提示进行操作即可。同时TransWe还是一款完全免费的小程序,旨在为用户提供更便捷、高效的翻译服务。无论是旅行、学习还是工作,TransWe都能帮助用户轻松应对语言难题。
🚀 功能特性
TransWe是一款集多种功能于一身的微信小程序,旨在为用户提供便捷、高效的翻译服务。以下是TransWe的主要功能特性:
- 多语言机器翻译:TransWe支持多种语言的翻译,包括但不限于英语、中文、法语、德语、日语、韩语等。我们的后台机器翻译服务能够快速、准确地翻译用户的文本,满足用户在不同场景下的翻译需求。
- OCR识别:TransWe集成了第三方OCR识别技术,用户只需上传图片或拍摄照片,我们的小程序就能将图片中的文字识别出来,转换为文本进行翻译。这一功能特别适用于处理图片中的外语文字,极大地提高了用户的翻译效率。
- 语音识别:TransWe支持第三方语音识别技术,用户只需录制音频,我们的小程序就能将音频中的语音识别并转换为文本进行翻译。这一功能使得用户在无法输入文字时,仍然可以轻松获取翻译服务。
- 语音合成:TransWe集成了第三方语音合成技术,用户可以将翻译结果转换为语音输出,提高了用户的交互体验,特别适用于视力不便或者需要听力辅助的用户。
TransWe的使用非常简单,用户只需选择需要翻译的语言,输入要翻译的文本,我们的小程序就会自动完成翻译。如果用户需要使用OCR识别、语音识别或语音合成功能,只需选择相应的功能按钮,按照提示进行操作即可。
TransWe是一款完全免费的小程序,我们的目标是为用户提供最便捷、高效的翻译服务。无论是旅行、学习还是工作,TransWe都能帮助用户轻松应对语言难题,让语言交流变得无障碍。
🧱 目录结构描述
1 | . |
⬇️ 版本内容更新
- 2023/06/02 TransWe v1.0: 基本实现全部功能
📃 协议
警告
除GPLv3许可下的源代码外,其他方均禁止使用TransWe的名义作为下载器应用,TransWe的衍生产品亦同。
衍生品包括但不限于分叉和非官方构建。
1.2 Github仓库地址
TransWe: https://github.com/dekrt/TransWe
1.3 人员基本分工
1.3.1 dekrt(负责人):
作为项目的负责人,dekrt将承担项目的后端开发工作,工作内容丰富且富有挑战性,主要包括:
- 负责Github仓库管理:dekrt将负责整个Github仓库的管理工作,包括代码的整理、归档以及版本的管理。他还将负责编写详实的README文档,以便于其他团队成员以及可能接触项目的人对项目有明确的了解。
- 将需求作为Issue录入:为了保证项目开发的流畅进行,dekrt将负责将所有的需求作为Issue录入Github,这样可以保证每一个需求都能被详细跟踪,从而高效地进行项目管理。
- 共同进行系统设计:他将积极参与系统设计,利用他的技术专长帮助设计出高效且易于维护的系统。
- 用户界面设计:dekrt将负责用户界面的设计和开发,他会注重用户体验,致力于创建出既易于使用又美观的用户界面。
- 系统流程分析:他将通过绘制时序图进行系统流程分析,这有助于更好地理解和设计系统。
- TDD测试:dekrt将采用测试驱动开发(TDD)的方法,为代码编写详尽的单元测试,以确保代码的质量和稳定性。
- 机器翻译服务:dekrt将负责与后台机器翻译服务的接口开发和维护,他将通过技术手段,确保翻译服务的准确性和效率,提供优质的用户体验。
- 拍照翻译服务:他还将负责开发拍照翻译服务,使用户能够通过拍照的方式获得翻译结果,为用户提供更多的便利。
- 前端页面编写:dekrt将完成
index(小程序主页)、getPic拍照界面)、OCR(获取翻译结果)、history(翻译历史)等页面的前端和后端代码编写,他将负责实现用户界面设计,同时也会对代码进行详细的测试,以保证其正确性和稳定性。 - 数据库管理:他将负责数据库的设计和管理,通过合理的数据结构设计和索引优化,确保用户数据的安全和完整。
- 性能优化:dekrt将专注于系统的性能优化,通过合理的代码架构和算法优化,他将确保系统在高并发情况下的稳定运行。
- 编写文档:为了保证项目的可维护性和持续性,他将负责编写清晰且详细的开发文档,以便于后续的开发和维护工作。
1.3.2 cdt(副负责人):
cdt将主要负责项目的前端开发和用户体验设计,包括但不限于:
- 共同撰写需求:一起参与需求讨论和构思,确保对项目的理解一致,从而能够产生详尽而有用的项目需求文档。在撰写需求过程中,努力保证每个要求都准确、清晰,易于理解且可行。
- 共同进行系统设计: 在深入理解了项目需求之后,参与到系统设计中来。确保每个设计决策都能满足项目的需求,同时也会考虑到系统的可扩展性和可维护性。
- 辅助用户界面设计:优化部分用户页面,以用户为中心,优化用户体验,使其简单易用。
- 系统设计:参与系统架构的设计,负责组件设计以及组件接口的设计。
- 语音合成功能:负责语音合成功能的开发和测试,和相关页面集成,确保这些功能的正常运行。
- 组件开发:负责components中五个小组件的开发和测试,每一个小组件都将被精心设计和编写,以确保它们在整个系统中都能发挥关键的作用。
- 页面编写:完成了choose_languege(语言选择页面)、edit(文本编辑页面)、voice_translation(语音翻译页面)这几个页面的前端、后端代码编写,实现了用户界面设计,和界面的逻辑功能,并进行了测试
- 编写文档:包括但不限于设计文档、开发文档、测试文档。
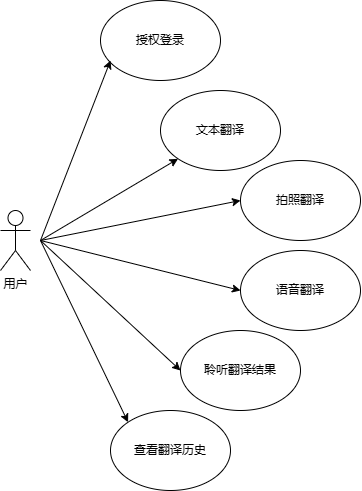
2. 需求描述
2.1 功能性描述
2.1.1 用户需求
1 集成翻译服务(Translation Service)
- 用户需求:
- 用户在输入框中输入文字,选择输入语言与目标语言,程序在输出框中给出翻译结果。
- 用户需求标识:TransWe-UR-TS
2 集成第三方OCR功能(Optical Character Recognition)
- 用户需求:
- 用户可以选择使用图片转文字服务(OCR),并进行拍照(或选择图库中的图片)进行翻译。
- 用户需求标识 :TransWe-UR-OCR
3 集成第三方语音识别(Speech Recognition):
- 用户需求:
- 用户选择输入语言及目标语言,通过语音进行输入,程序以文字形式展示输入结果与翻译结果。
- 用户需求标识:TransWe-UR-SR
4 集成第三方语音合成(Speech Synthesis)
- 用户需求:
- 用户在翻译完成后点击发声按钮,程序将翻译结果以语音的形式进行输出。
- 用户需求标识:TransWe-UR-SS
2.1.2 系统需求
1 基础翻译功能(TransWe-SR-TS)
- 初始假设:
- 用户在输入框中输入文字,选择输入语言与目标语言,程序在输出框中给出翻译结果。
- 正常状态:
- 用户在输入框中输入待翻译的文本,程序会自动检测输入语言,用户在下拉菜单中选择相应的目标语言。
- 用户也可以手动选择输入语言。输入完成后,程序将进行翻译并在输出框中显示翻译结果。
- 有哪些会出错:
- 输入的文本中包含无法识别的字符或语言。程序会提示用户重新输入或手动选择语言。
- 输入的文本过长或复杂,程序无法进行翻译。程序会提示用户缩短输入文本或尝试其他翻译方式。
- 网络连接不稳定,程序无法进行翻译。程序会提示用户检查网络连接并重试。
- 其他活动:
- 用户可以在下拉菜单中选择默认语言,程序会在下一次启动时自动选择该语言。
- 程序会记录用户的翻译历史,并允许用户在历史记录中查看以前的翻译结果。
- 完成的系统状态:
- 用户可以通过打开程序,并进入翻译界面来进行翻译。程序会自动检测输入语言,并在下拉菜单中选择相应的目标语言。
- 用户在输入框中输入待翻译的文本后,程序会进行翻译并在输出框中显示翻译结果。
- 程序记录了用户的翻译历史,并允许用户在历史记录中查看以前的翻译结果。
2 集成第三方OCR功能的脚本(TransWe-SR-OCR)
- 初始假设:
- 用户需要使用一个微信翻译小程序,该小程序集成了第三方OCR功能,用户可以通过拍照或上传照片将图片中的待翻译文本识别成目标语言并显示到图片上。
- 正常状态:
用户打开小程序,选择OCR功能,进入拍照界面。用户可以使用手机摄像头拍下待识别的图片,也可以按下图库按钮上传照片。进入图片编辑界面后,用户可以选择整张图片或者框选一部分图片,用户需要选择待翻译的语言种类和目标语言种类。检测到用户按下翻译按钮时,系统应该调用OCR服务对目标图片进行文字识别,并在界面上显示识别结果。
系统应该允许用户在翻译后重新选择图片,重新选择翻译语言并进行翻译。
- 有哪些会出错:
- 系统权限不足,无法访问用户图库。
- 第三方OCR功能出现故障,导致无法完成文字识别。
- 其他活动:
- 系统应该保证用户隐私,不记录用户的OCR识别记录。
- 系统应该对用户图库进行保护,确保不被未授权的其他脚本访问。
- 完成的系统状态:
- 用户可以通过OCR功能成功识别图片中的文字并进行翻译。
3 语音识别功能(TransWe-SR-SR)
- 初始假设:
- 用户希望通过语音输入来输入翻译内容,系统需要进行语音识别功能,将语音转换为文本,再进行翻译操作。
- 正常状态:
- 用户点击语音输入按钮,系统开始录音并将录音转换为文本格式,并输出到屏幕上。
- 系统对文本进行分词并进行翻译操作。
- 翻译结果以文本形式呈现在界面上。
- 有哪些会出错:
- 语音输入的质量不好,无法被识别成文本。系统应该提示用户录音质量不好,请重试。
- 翻译服务不可用或异常。系统应该提示用户翻译服务暂时不可用,请稍后再试。
- 其他活动:
- 系统应该保证用户隐私,不记录用户的语音输入内容。
- 系统应该对录音文件进行保护,确保不被未授权的人访问。
- 完成的系统状态:
- 用户可以通过语音输入方式进行翻译操作。
- 系统可以对语音进行识别并将其转换为文本格式。
- 系统可以对文本进行分词和翻译操作,将翻译结果呈现在界面上。
4 语音合成功能(TransWe-UR-SS)
- 初始假设:
- 用户希望通过语音的形式来输出翻译内容,系统需要进行语音合成功能,将文本转换为语音,再通过扬声器播放。
- 正常状态:
- 用户正常进行翻译后,点击语音输出按钮,系统开始进行语音合成并将翻译结果以语音的形式进行输出。
- 翻译结果以文本形式呈现在界面上。
- 有哪些会出错:
- 系统语音合成功能出现故障,无法将文本正确转换为语音。
- 扬声器或音频设备出现故障,无法正常播放语音。
- 其他活动:
- 当正在播放合成的语音时,图标的颜色将会改变;播放完成后回到原来的颜色。
- 完成的系统状态:
- 用户可以通过语音输入并输出翻译内容,系统可以将文本转换为语音,并通过扬声器播放出来。系统记录了用户的输入和输出内容,并可以对其进行分析和统计。
2.2 非功能性需求
2.2.1 性能需求:
- 翻译响应时间:对于用户输入的文本,系统应在1秒内返回翻译结果。
- OCR识别和语音识别的处理时间:对于用户上传的图片或音频,系统应在5秒内完成识别并返回结果。
- 系统应能够支持高并发请求,即在用户量剧增的情况下,系统的性能不会显著下降。
2.2.2 安全性需求:
- 用户的个人信息和使用数据应得到充分保护,不得泄露给第三方。
- 系统应具备防止恶意攻击的能力,如DDoS攻击、SQL注入等。
2.2.3 可用性需求:
- 系统的正常运行时间应达到99.9%。
- 在出现故障时,系统应能在1小时内恢复正常。
2.2.4 可维护性需求:
- 系统应具备良好的模块化和文档化,以便进行维护和升级。
- 系统应能够容易地添加新的语言支持和新的功能。
2.2.5 可扩展性需求:
- 系统应设计成可扩展的架构,以便在未来可以添加更多的功能,如多语言支持、语音翻译等。
2.2.6 用户体验需求:
- 系统的用户界面应简洁易用,用户能够快速理解如何使用各项功能。
- 系统应提供用户反馈功能,用户可以方便地报告问题和提出建议。
3. 系统设计
3.1 架构设计
我们的翻译小程序采用分层架构的架构模式,架构示意图如下:
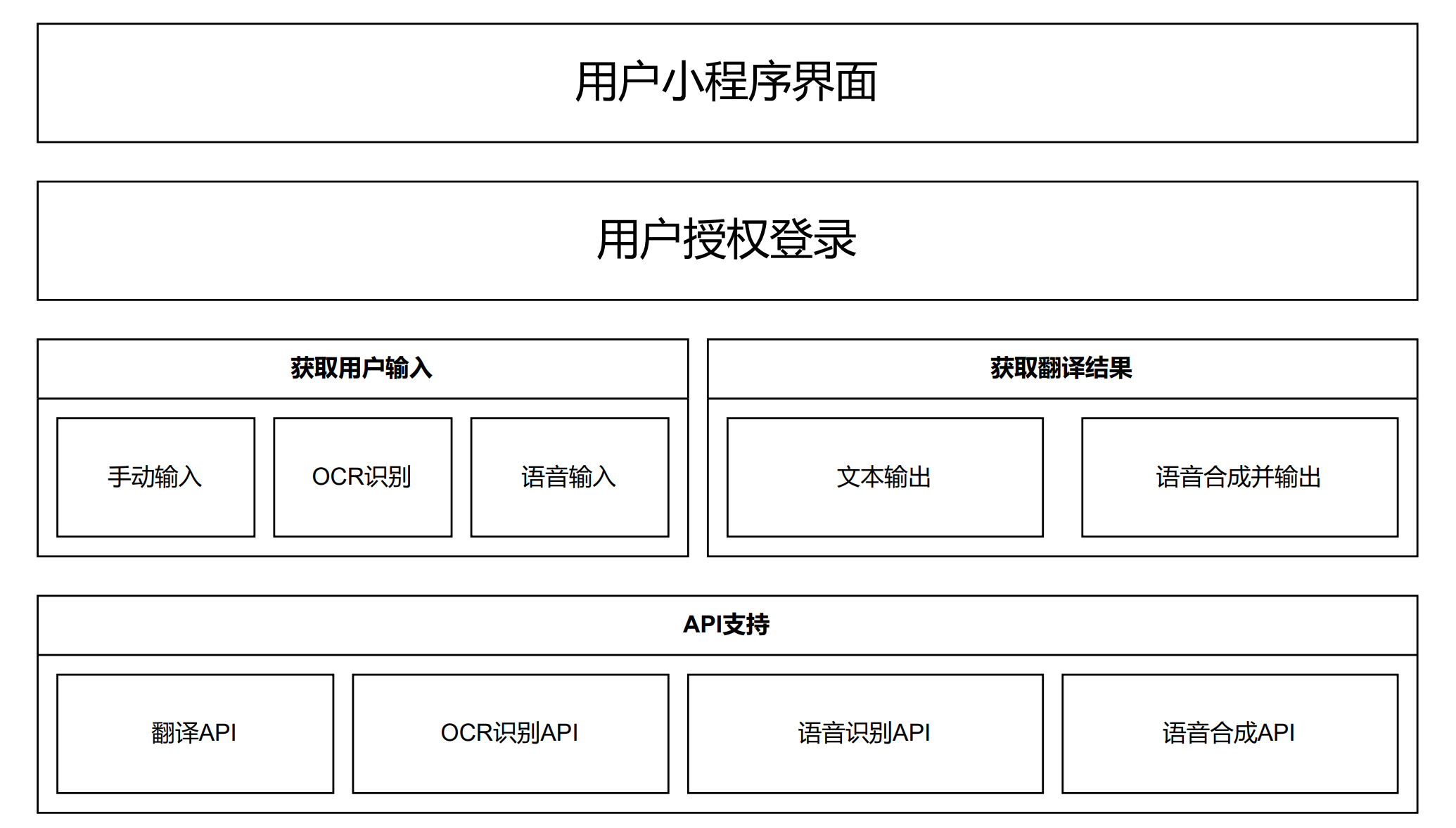
3.1.1 表示层(Presentation Layer)
表示层是用户与系统交互的界面,包括用户界面、数据输入、输出等。这一层主要负责将用户请求传递给下一层,并将处理结果返回给用户。在我们的翻译软件中,表示层包括用户输入文本的界面、显示翻译结果的界面、对翻译结果进行输出的页面等,以及获取用户的授权信息。
3.1.2 应用层(Application Layer)
应用层是系统的核心层,它实现了翻译的核心算法和业务逻辑,包括文本处理、翻译算法等。这一层主要负责接收并处理表示层传递的请求,然后调用其他层的服务,最后将处理结果返回给表示层。在我们的小程序中,应用层负责:
- 获取用户输入:
- 手动输入
- OCR识别
- 语音输入
- 获取输出结果:
- 文本输出
- 语音合成输出
3.1.3 服务层(Service Layer)
服务层为应用层提供支持,包括网络通信、数据访问、存储等服务。这一层主要负责处理数据的存储和访问,以及与其他系统的交互。在我们的翻译软件中,服务层可以包括调用翻译接口获取翻译结果、调取OCR接口获取OCR识别结果、调取语音合成API对翻译结果进行语音输出等。
总的来说,以上三个层级构成了一个完整的翻译软件系统,每个层级都负责不同的功能,各司其职。这种分层架构模式使得系统更加清晰、易于扩展和维护。
3.2界面原型设计
3.2.1. 主页面(Main Page)
主页是小程序的入口,包括小程序的基本信息和主要功能模块。页面包含四个模块,分别是文字翻译,录音按钮、OCR翻译按钮和翻译历史记录。
- 文本输入框:用户可以在这个框中手动输入需要翻译的文本。
- 翻译框:用户输入文本、点击这个按钮开始翻译。
- 语音播放器:用户点击播放语音。
- 语言选择器:用户可以在这里选择源语言和目标语言。
- 语音按钮:用户可以点击这个按钮,跳转到语音翻译页面。
- OCR按钮:用户可以点击这个按钮,跳转到语音OCR页面。
- 翻译历史按钮:用户可以点击这个按钮,跳转到翻译历史页面。
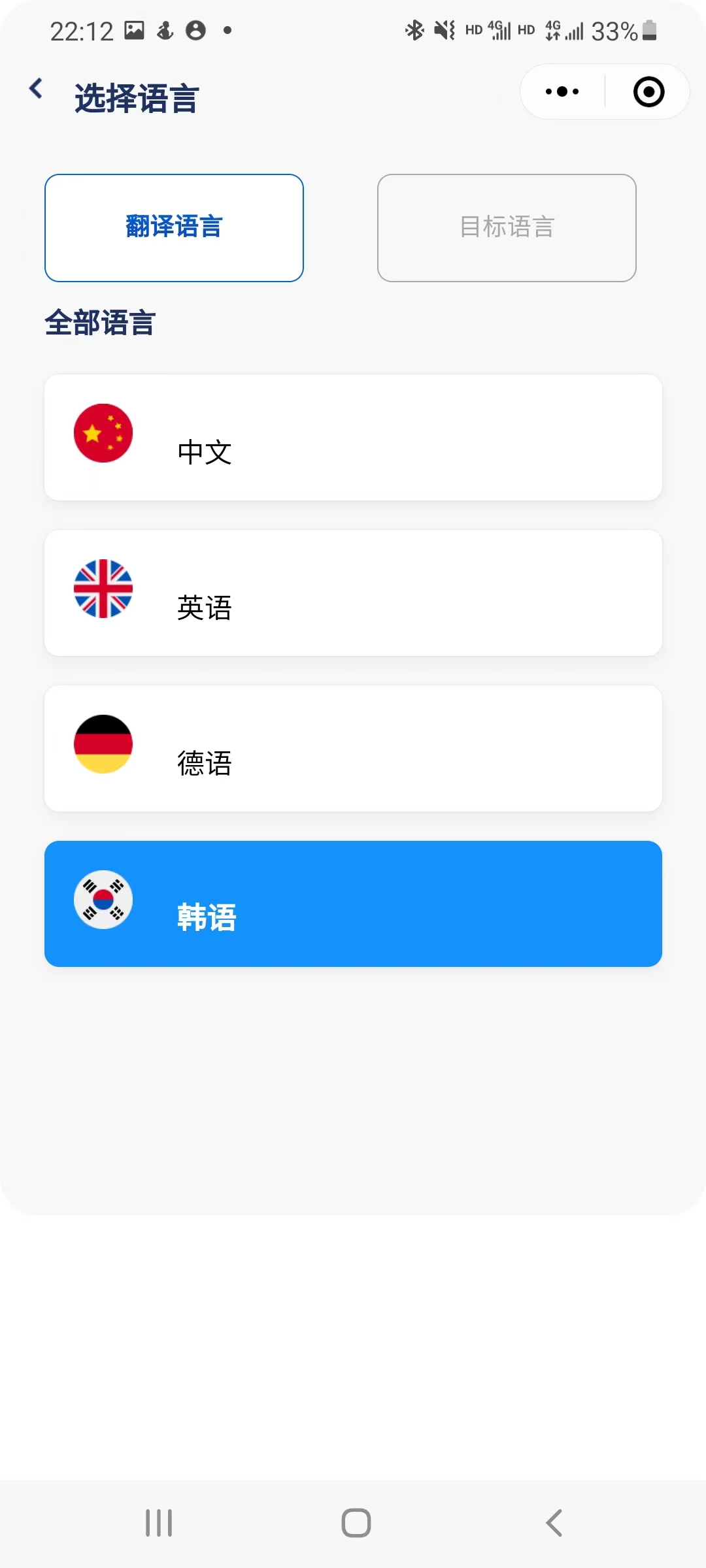
3.2.2.语言选择页(Settings Page)
语言选择页提供用户多种翻译语言。用户可以选择支持的语言。
- 语言设置:用户可以在这里更改默认的源语言和目标语言。
3.2.3.语音翻译页(Voice Translation Page)
语音翻译页是用户输入需要翻译的语音的页面。页面主要包括录音按钮、语言选择器和翻译结果框。翻译结果框会以卡片形式保存下来,用户可以编辑录入的文字。
- 录音按钮:位于页面下方,用户可以点击此按钮开始进行语音输入,输入的语音将被实时转化为文字并显示在结果框内。
- 语言选择器:位于页面顶部,用户可以在此一键切换中英文。
- 翻译结果框显示用户录音输入的文字以及翻译结果。翻译结果以卡片形式保存并展示,每个卡片包括原文和译文,用户可以删除不要的卡片。
- 编辑按钮:每个翻译结果卡片右上角都会有一个编辑按钮,用户点击后可以对录入的文字进行编辑,编辑完成后翻译结果将自动更新。
- 返回按钮:页面左上角有一个返回按钮,用户点击后可以返回主页面。
3.2.4.OCR拍照翻译页面(OCR Translation Page)
OCR拍照翻译页面是用户能够通过拍照进行翻译的地方。
- 拍照按钮:用户可以点击这个按钮,利用手机相机进行拍摄,完成拍摄后,系统会自动进行识别并将图片中的文字进行翻译。
- 翻译结果展示区:系统完成翻译后,翻译结果将会在这个区域显示,用户可以查看翻译结果。
3.2.5.翻译历史页(Translation History Page)
翻译历史页面保存用户之前的文字翻译和语音翻译记录。
- 翻译历史:用户可以划动屏幕查询所有的本地翻译记录。每条历史以卡片形式保存并展示,每个卡片包括原文和译文。
3.3 详细设计
3.3.1. 组件设计
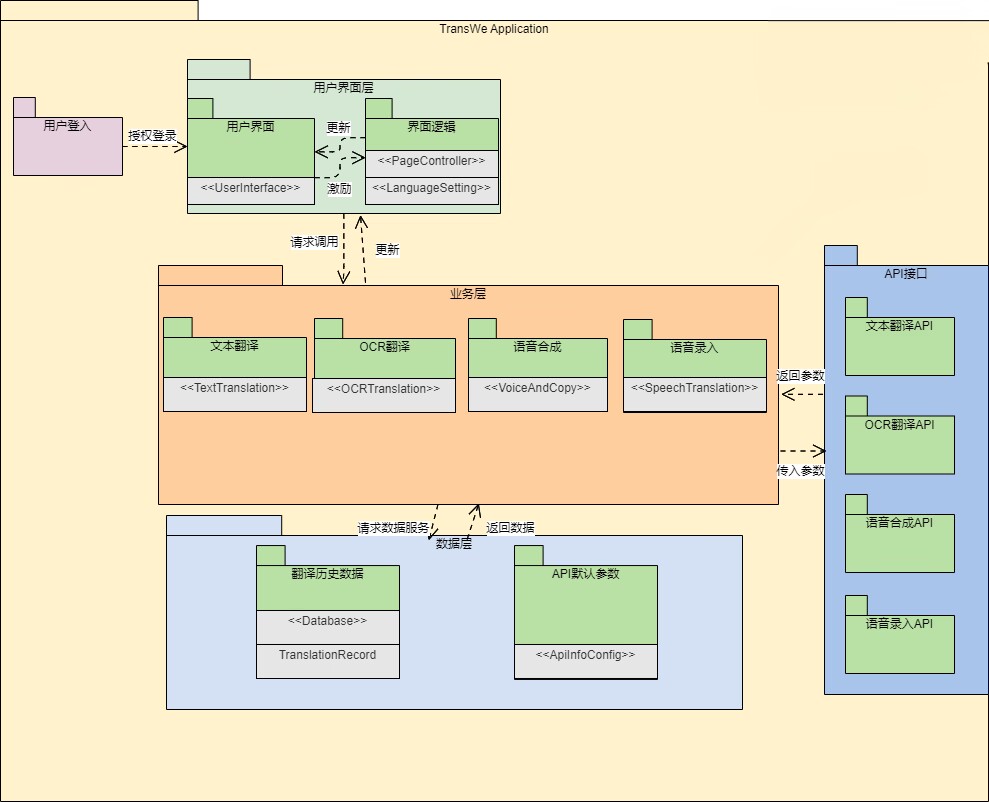
3.3.2. 组件接口设计
1 数据库接口

saveTranslationRecord(record: TranslationRecord): void:保存翻译记录。getTranslationRecords(userId: String): List<TranslationRecord>:获取指定用户的翻译记录列表。
2 语言设置接口

sourceLanguage: String:源语言属性。targetLanguage: String:目标语言属性。setSourceLanguage(sourceLanguage: String): void:设置源语言。setTargetLanguage(targetLanguage: String): void:设置目标语言。getSourceLanguage(): String:获取源语言。getTargetLanguage(): String:获取目标语言。
3 OCR翻译接口
![]()
recognizeImage(image: ImageData, sourceLanguage: String, targetLanguage: String): String:将图像数据识别为文本,并将其翻译成指定的目标语言。
4 语音翻译接口
recognizeSpeech(audio: AudioData, sourceLanguage: String, targetLanguage: String): String:将音频数据识别为文本,并将其翻译成指定的目标语言。
5 文本翻译接口
translateText(text: String, sourceLanguage: String, targetLanguage: String): String:将指定的文本翻译成指定的目标语言。
6 用户界面接口
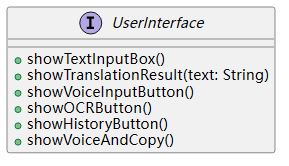
showTextInputBox(): void:显示文本输入框。showTranslationResult(text: String): void:显示翻译结果。showVoiceInputButton(): void:显示语音输入按钮。showOCRButton(): void:显示 OCR 按钮。showHistoryButton(): void:显示历史记录按钮。showVoiceAndCopy(): void:显示语音合成和复制按钮。
7 语音录入接口

getVoice(text: String, targetLanguage: String): AudioData:将指定的文本转换为语音,并返回音频数据。copyText(text: String): void:将指定的文本复制到剪贴板。
8 页面控制接口
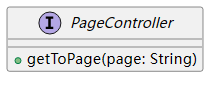
+getToPage(page: String):表示该接口具有一个公共方法getToPage,该方法接受一个参数page,类型为String,用于获取指定页面的内容。
9 API信息配置接口
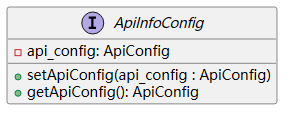
-api_config: ApiConfig:表示该接口具有一个私有属性api_config,其类型为ApiConfig。私有属性只能在该类内部访问。+setApiConfig(api_config : ApiConfig):表示该接口具有一个公共方法setApiConfig,该方法接受一个参数api_config,类型为ApiConfig,用于设置api_config的值。+getApiConfig(): ApiConfig:表示该接口具有一个公共方法getApiConfig,该方法返回api_config的值,类型为ApiConfig。
10 翻译记录
userId: String:用户 ID 属性。sourceText: String:源文本属性。sourceLanguage: String:源语言属性。targetText: String:目标文本属性。targetLanguage: String:目标语言属性。timestamp: DateTime:时间戳属性。getUserId(): String:获取用户 ID。getSourceText(): String:获取源文本。getSourceLanguage(): String:获取源语言。getTargetText(): String:获取目标文本。getTargetLanguage(): String:获取目标语言。getTimestamp(): DateTime: 获取时间戳。
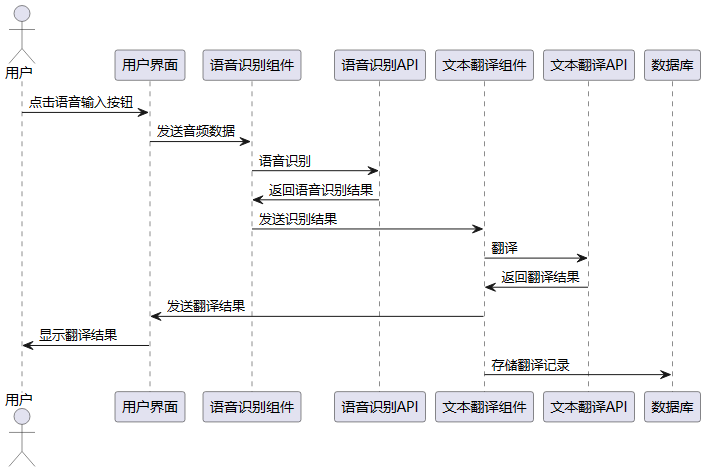
3.3.3 系统流程分析
结合上述用例图,我们得出以下的时序图:
1 文本翻译时序图
2 拍照翻译时序图
3 语音翻译时序图
4 语音合成时序图
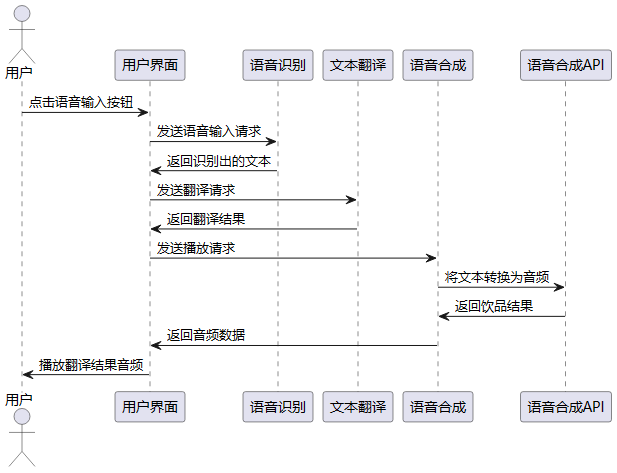
1 | @font-face {font-family: "iconfont"; |
1 | // 引入语言配置文件 |
1 | { |
1 | <!-- 按钮组容器,当hidden为true时隐藏 --> |
1 | /* 按钮组容器样式,使用flex布局,内容居中 */ |
1 | // 导入语言配置 |
1 | { |
1 | <!-- 如果modalShow为true,则显示模态框 --> |
1 | /* 模态框容器样式 */ |
1 | // 加载图标的路径 |
1 | { |
1 | <!-- 主视图,包含音乐播放图标 --> |
1 | /* 容器的样式 */ |
1 | // 引入语言配置 |
1 | { |
1 | <!-- 消息气泡容器,长按显示模态框 --> |
1 | /* 消息气泡容器 */ |
1 | // 定义小程序组件 |
1 | { |
1 | <view class="loading"> |
1 |
|
1 | // 获取全局应用实例 |
1 | { |
1 | <!-- 页面主体是一个垂直方向的 flex 布局 --> |
1 | /* 页面样式,包含内边距,背景色,宽度,溢出处理等样式 */ |
1 | //初始化底部高度 |
1 | {} |
1 | <!-- edit.wxml --> |
1 | /* pages/edit/edit.wxss */ |
1 | // 引入api模块,该模块可能包含了一些工具函数 |
1 | { |
1 | <!-- 头部视图 --> |
1 | /* 头部视图样式 */ |
1 | // 引入全局的app实例 |
1 | { |
1 | <!-- 可滚动视图,设置为纵向滚动 --> |
1 | /* 历史记录列表样式 */ |
1 | classDiagram |
1 | // 引入翻译工具和全局应用实例 |
1 | {} |
1 | graph TB |
1 | <!--index.wxml--> |
1 | .container { |
1 | // 导入翻译工具 |
1 | { |
1 | <!-- 头部视图 --> |
1 | /* 容器样式 */ |
1 | // 获取应用实例 |
1 | // 按住按钮开始语音识别 |
1 | /** |
1 | /** |
1 | /** |
1 | /** |
1 | { |
1 | <!--index.wxml--> |
1 | /* 主容器样式 */ |
1 | translateText: function(item, index) { |
1 | // translate.js |
1 | // 引入测试库 |
1 | import md5 from './md5.min.js' |
1 | let language = [ |
1 | ! function(n) { |
1 | const formatTime = date => { |
1 | // 导入工具模块 |
1 | { |
1 | /* 引入 iconfont 的样式文件 */ |
1 | { |
1 | { |
- 测试点2
- 测试点3
- 测试点4
测试通过数(4/4)
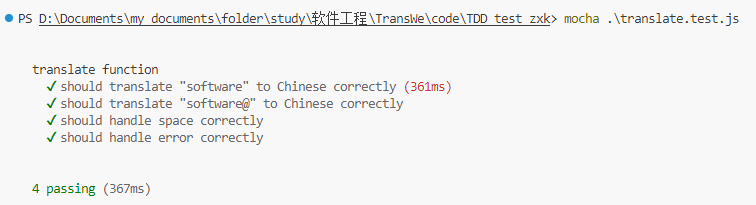
4.2.1.2 TDD_test_zxk/
基于Mocha框架编写的测试文本翻译Javascript的测试程序。
1 | // 引入测试库 |
若要进行测试,请在正确安装相关框架的情况下运行:
1 | mocha .\translate.test.js |
测试成功会显示下列截图:
5. 系统界面展示
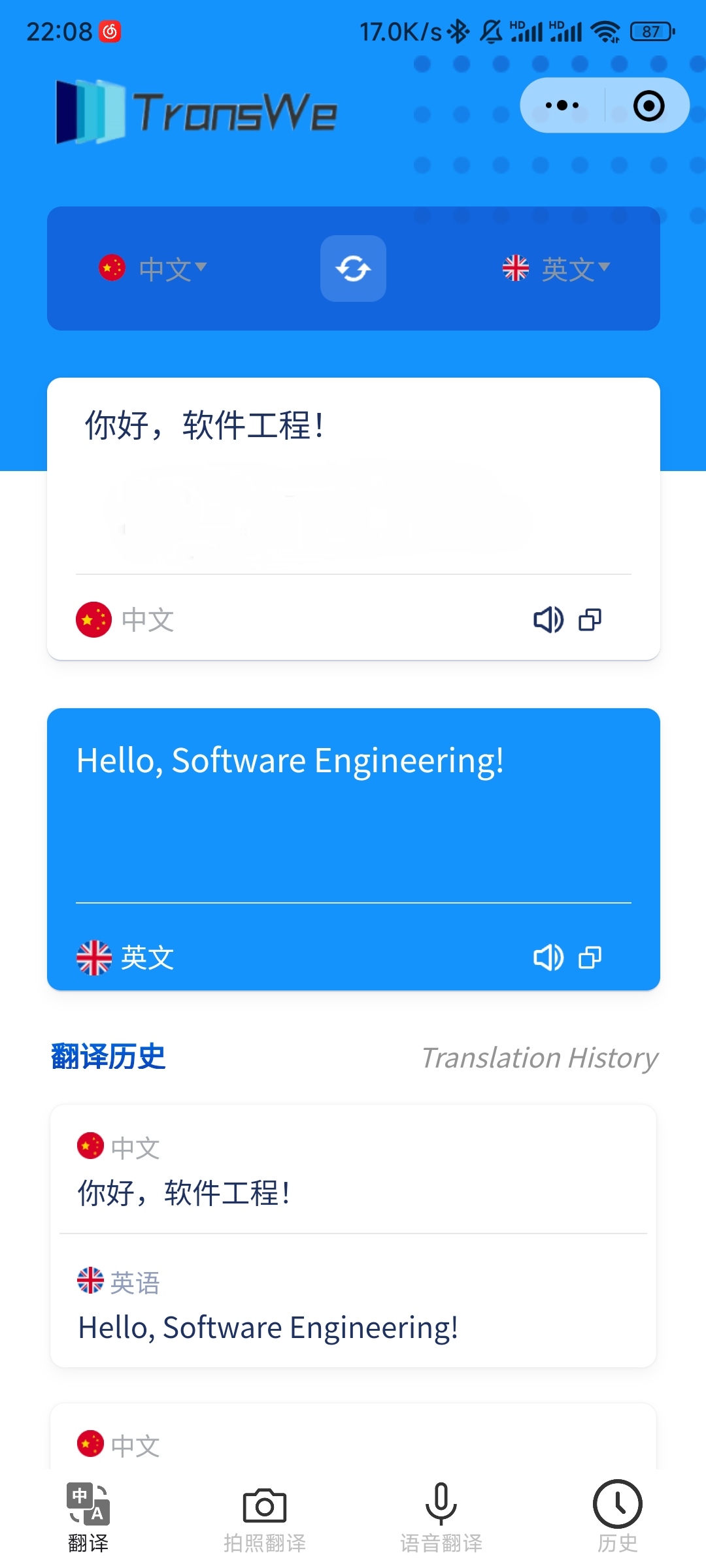
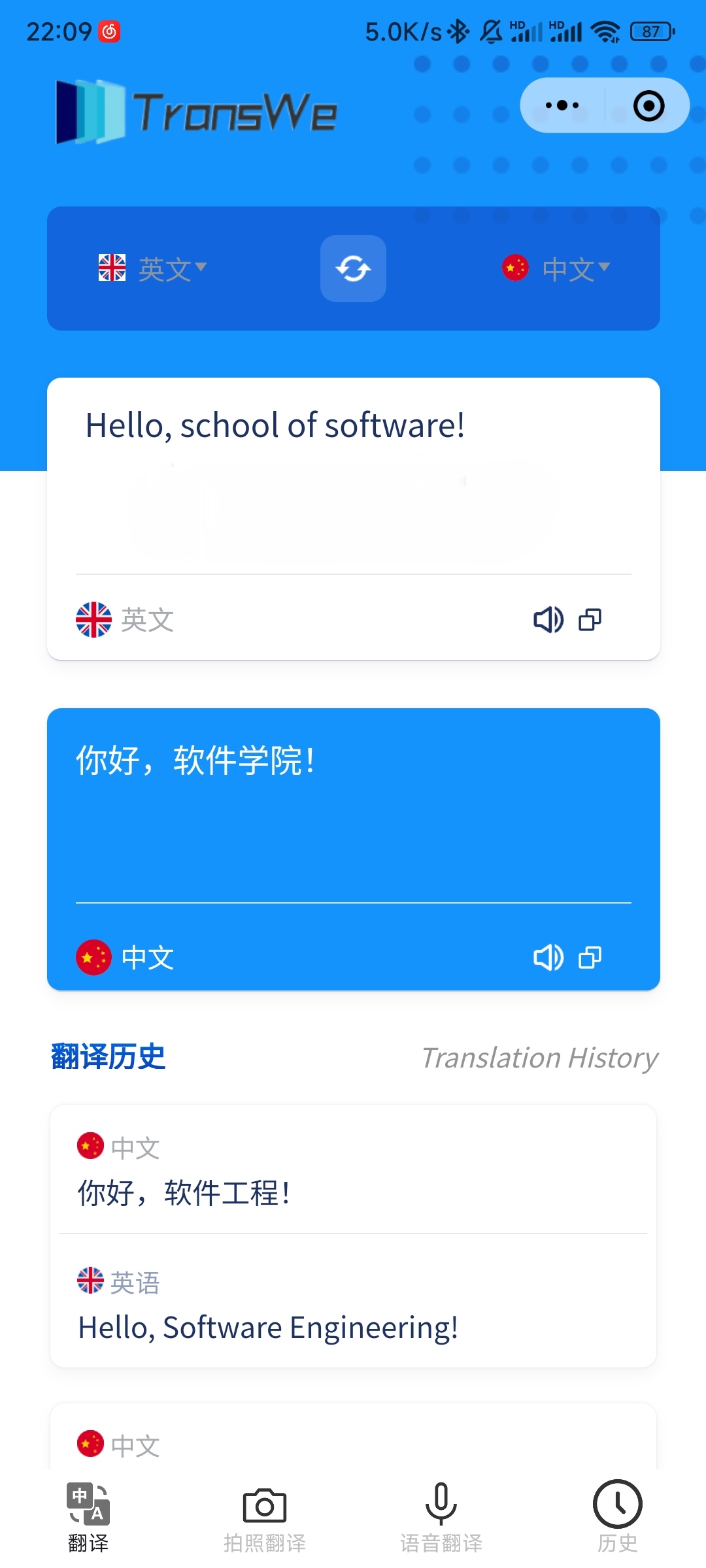
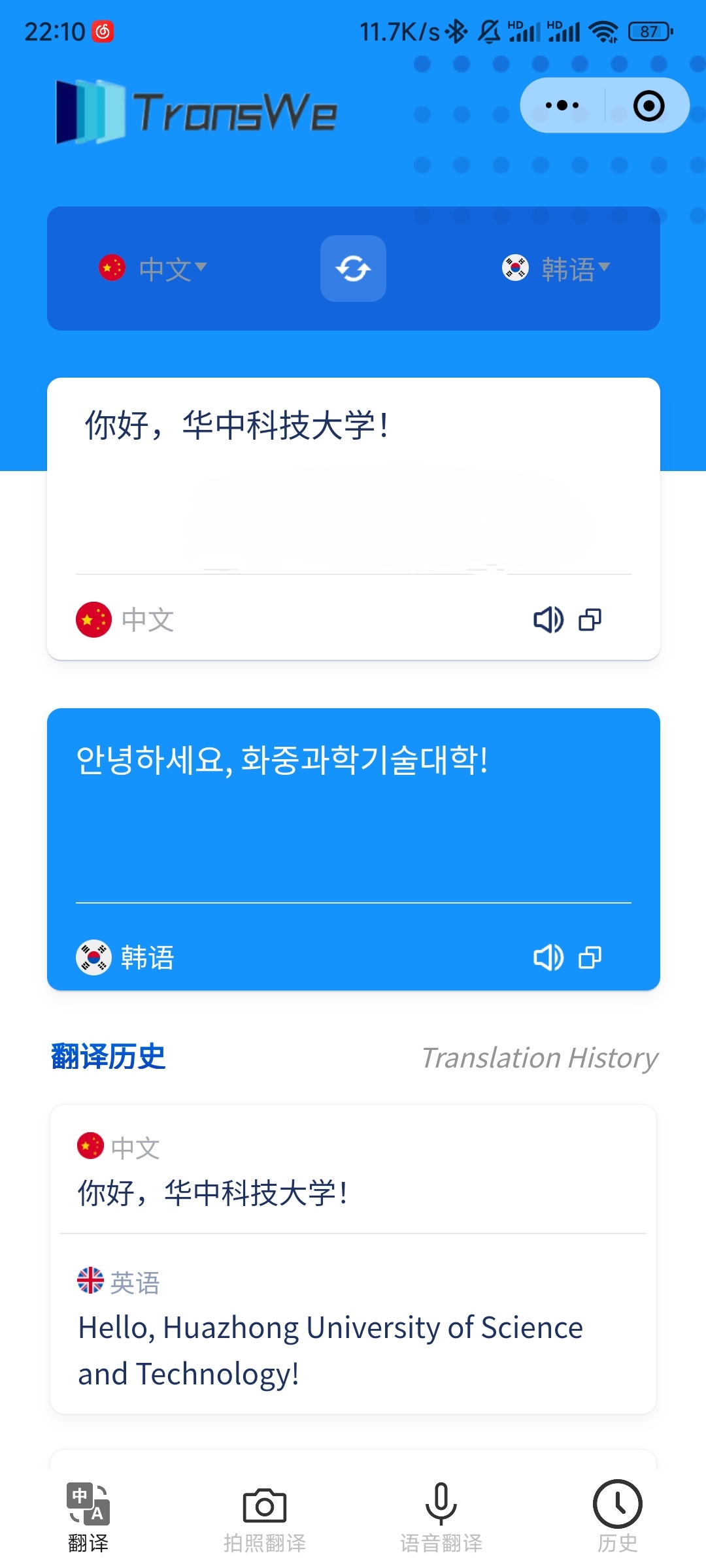
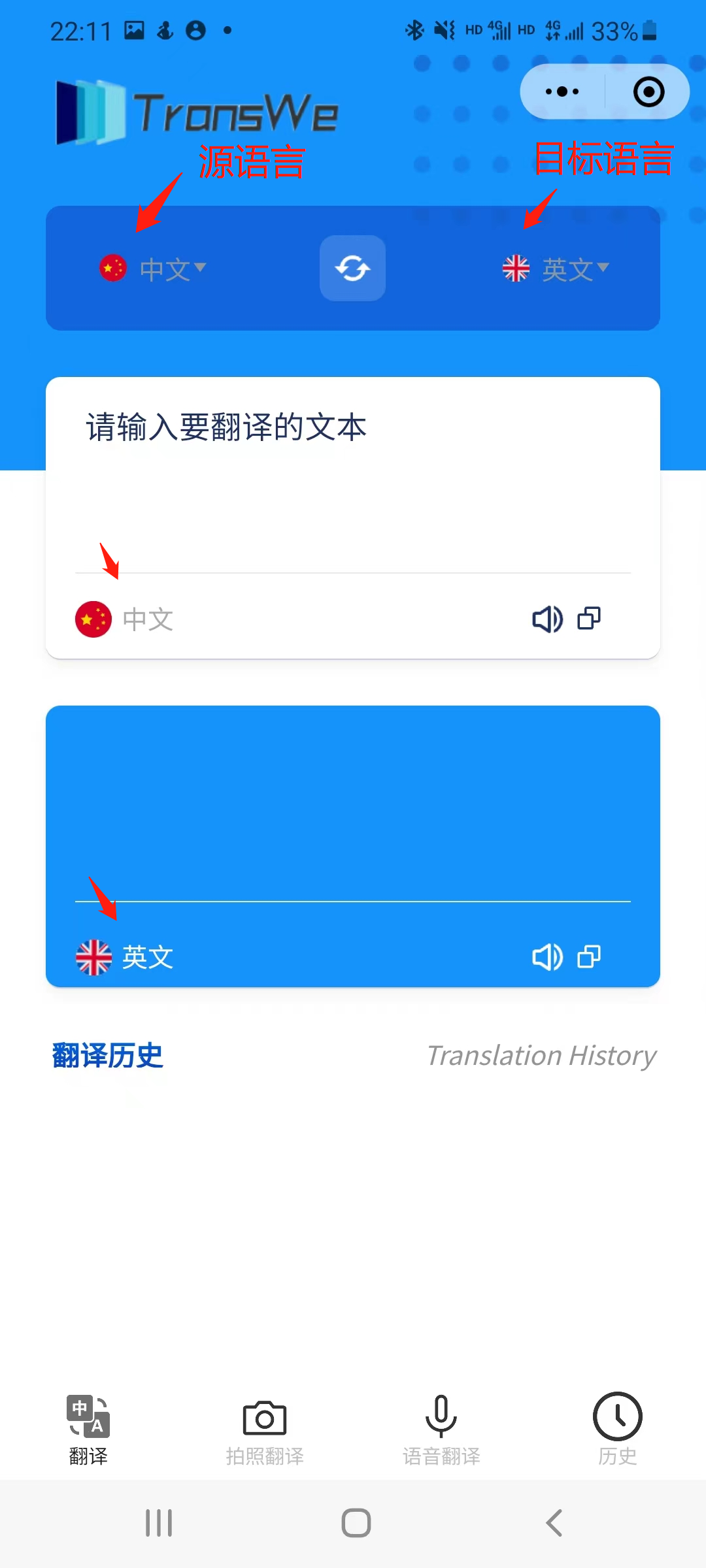
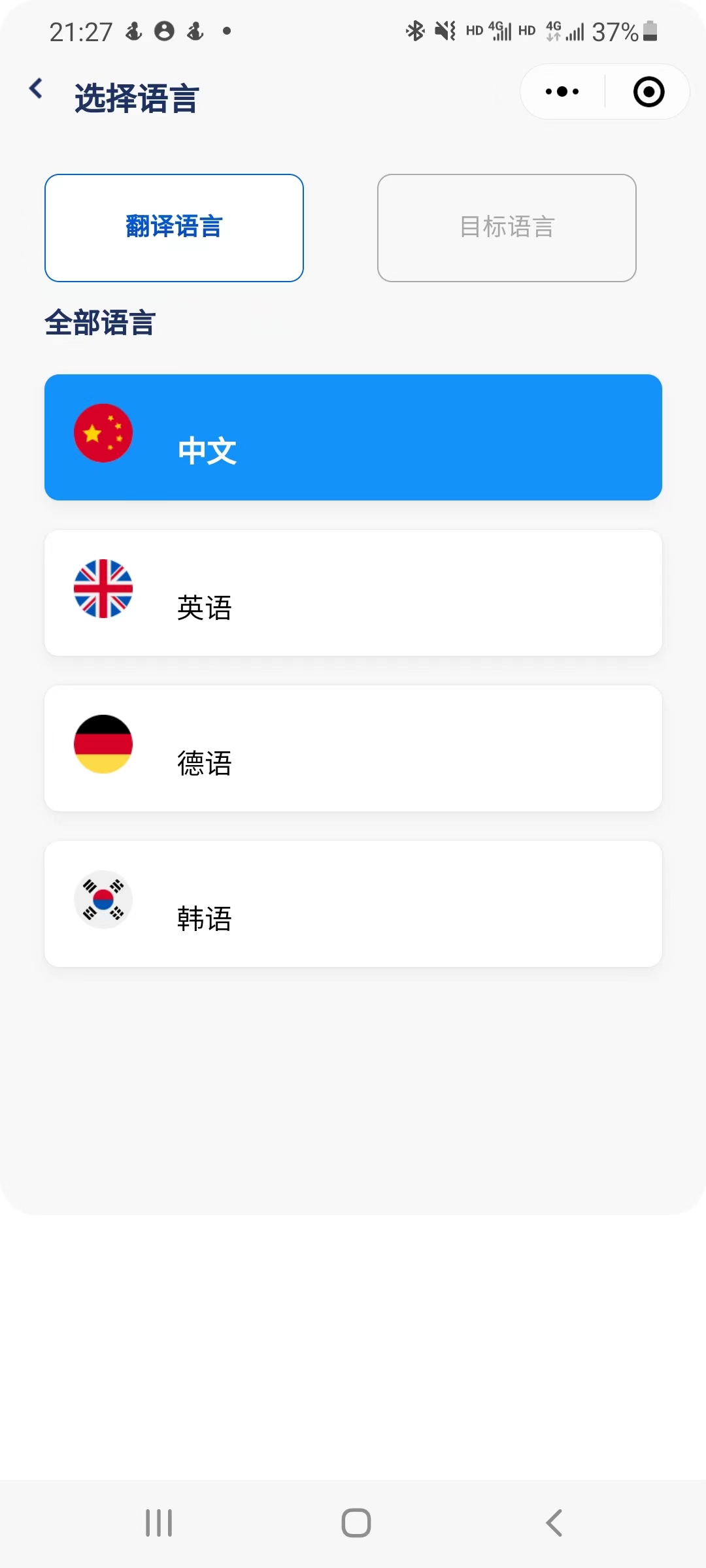
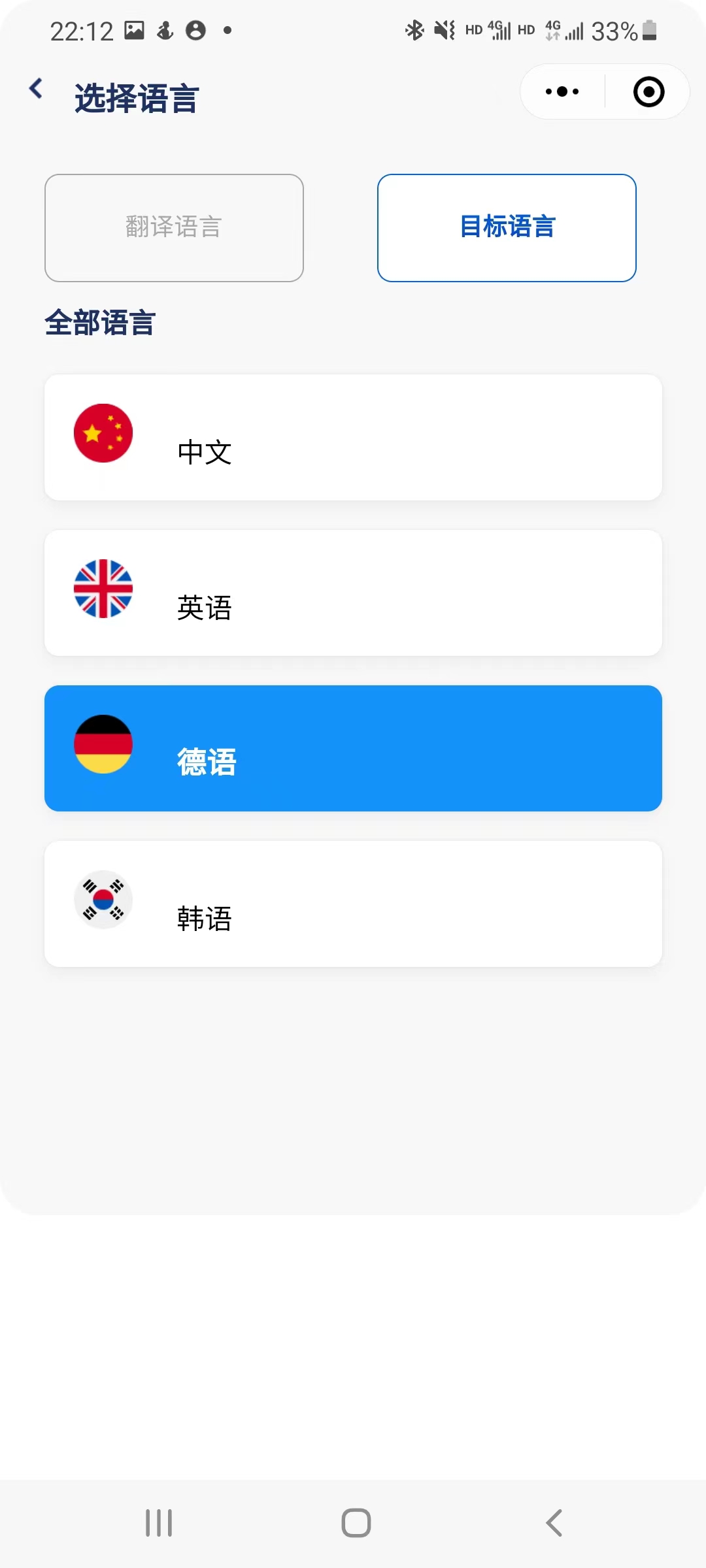
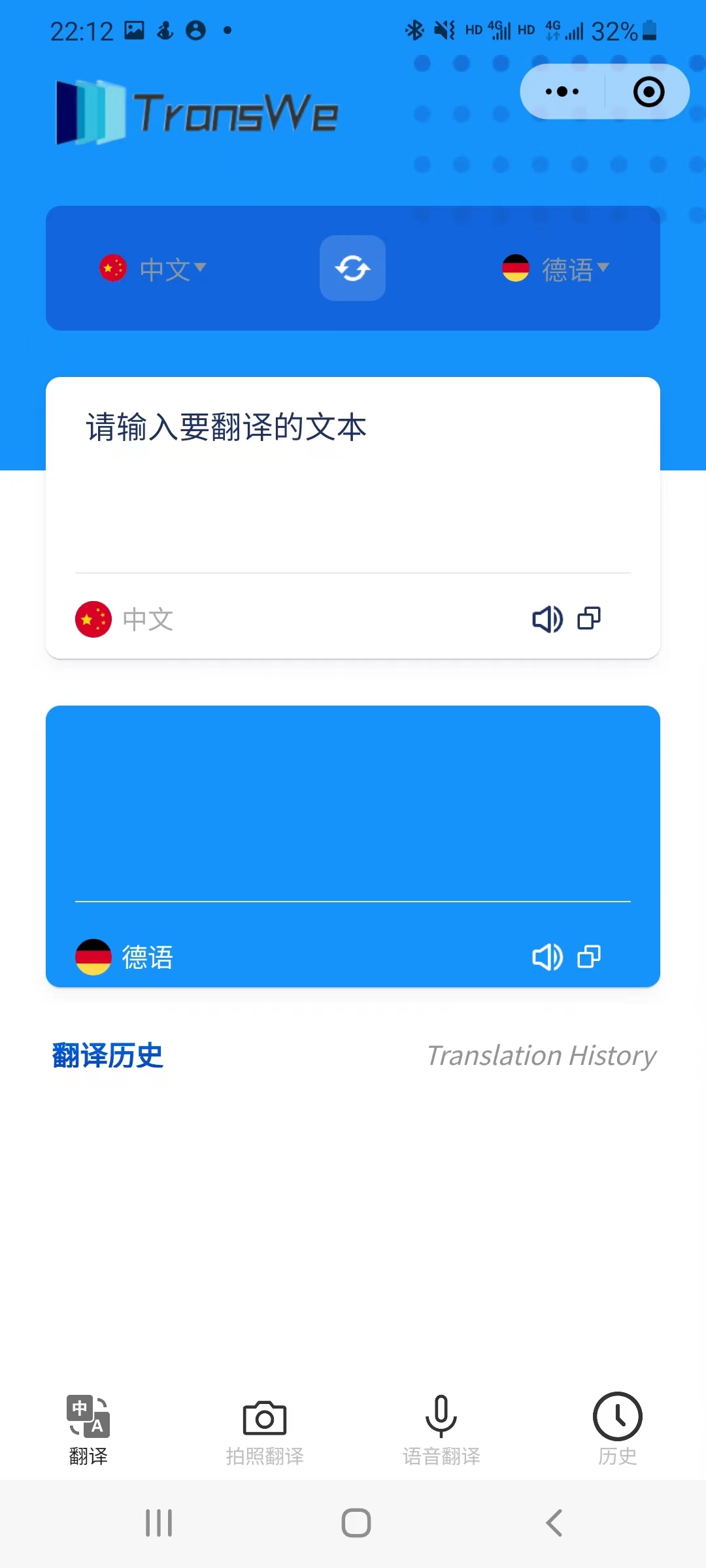
5.1 index | 主页
在主页中:
- 用户在输入框中输入待翻译的文本,程序会自动检测输入语言,用户在下拉菜单中选择相应的目标语言。
- 用户也可以手动选择输入语言。输入完成后,程序将进行翻译并在输出框中显示翻译结果。
- 用户可以点击小喇叭按钮,调用语音合成功能,听到翻译结果。
- 用户可以点击剪贴板按钮,待翻译文本或翻译结果会自动复制到用户的剪贴板。
- 用户可以点击下方的翻译历史板块,跳转到翻译历史页面。
- 用户可以点击最下方的导航栏跳转到对应的界面。
5.3 getPic | 拍照界面
在这个界面,用户点击拍照按钮可以进行拍照,并进入拍照翻译的结果页面。

5.4 OCR | 拍照翻译结果
在这个界面,点击翻译图片,小程序会进行OCR识别并进行翻译,将结果显示在屏幕上。

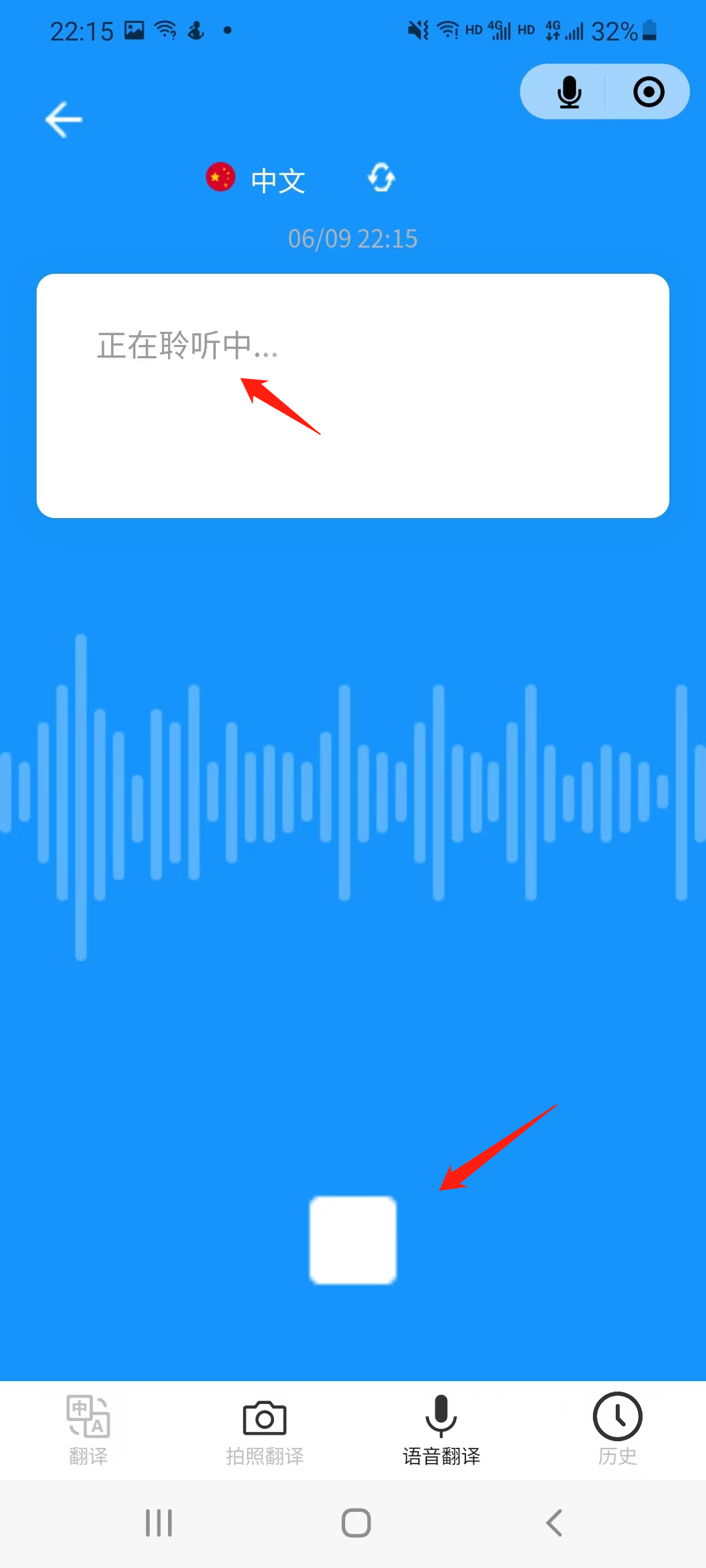
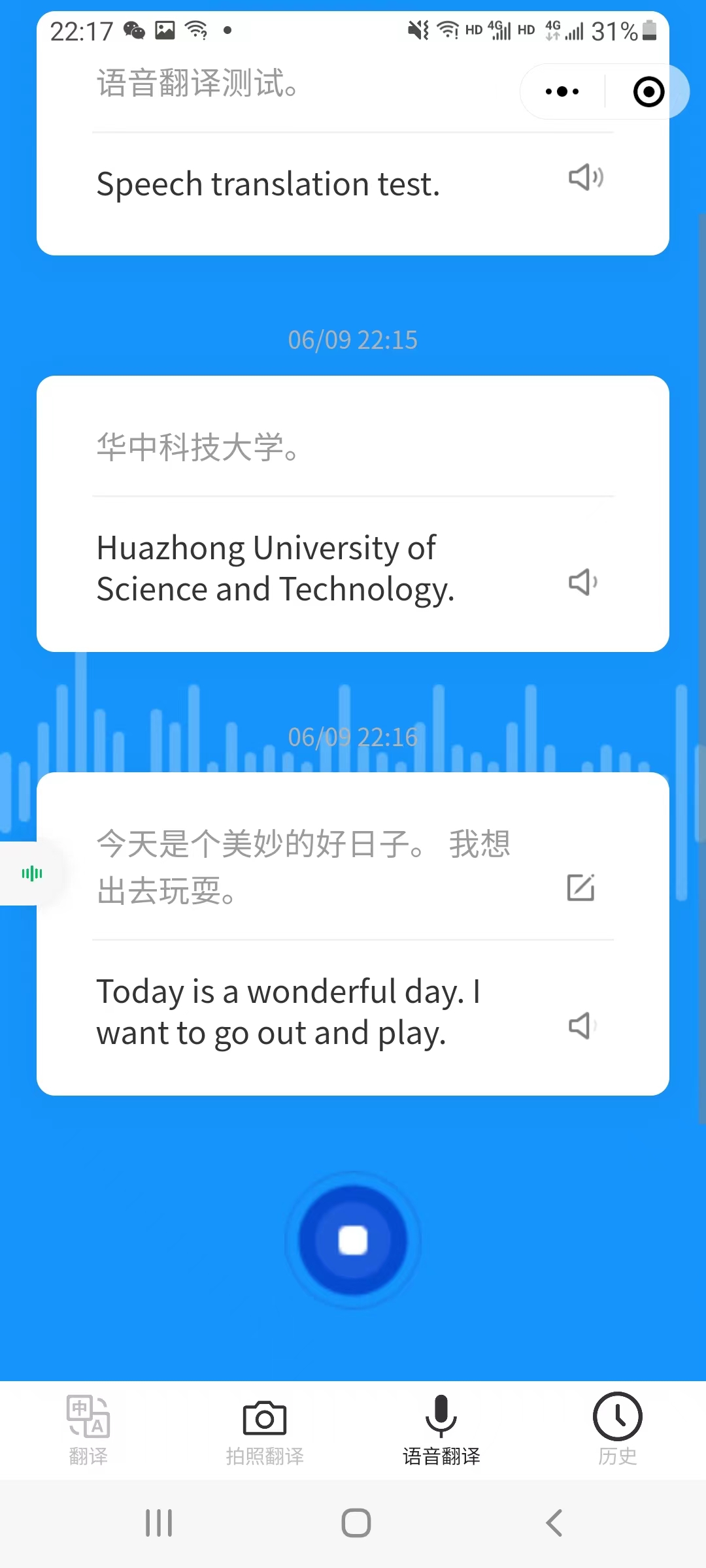
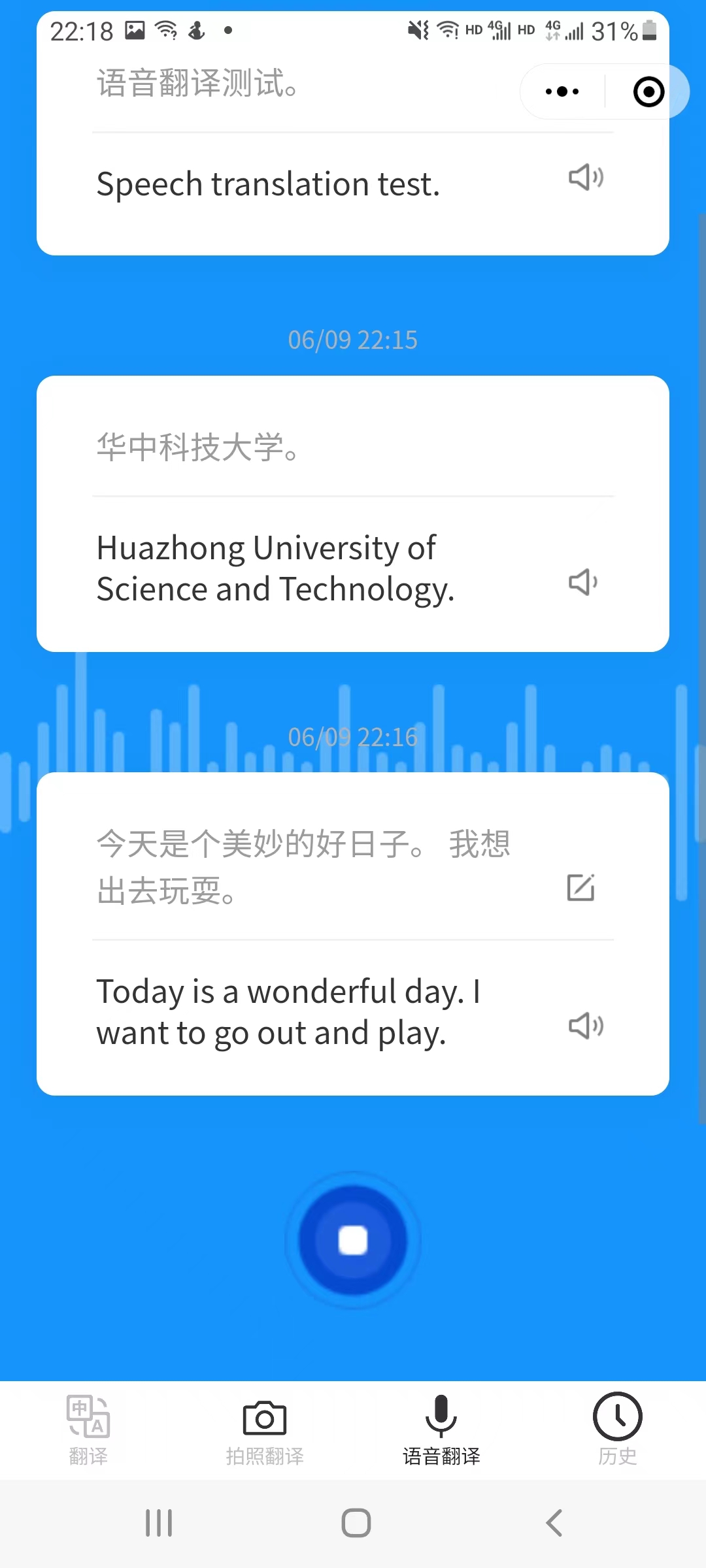
5.5 voice_translation | 语音翻译页面
语音翻译页面,点击切换按钮改变录音语言。

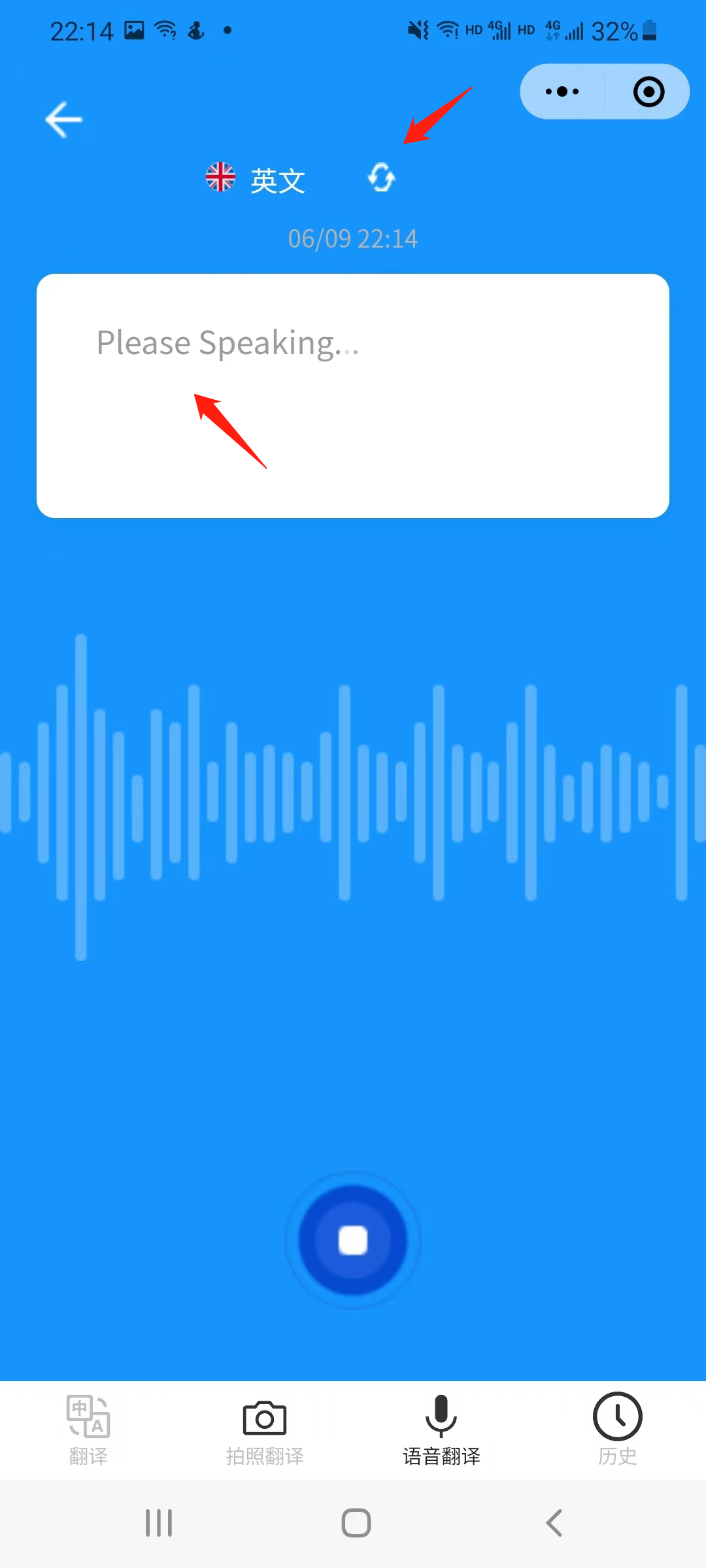
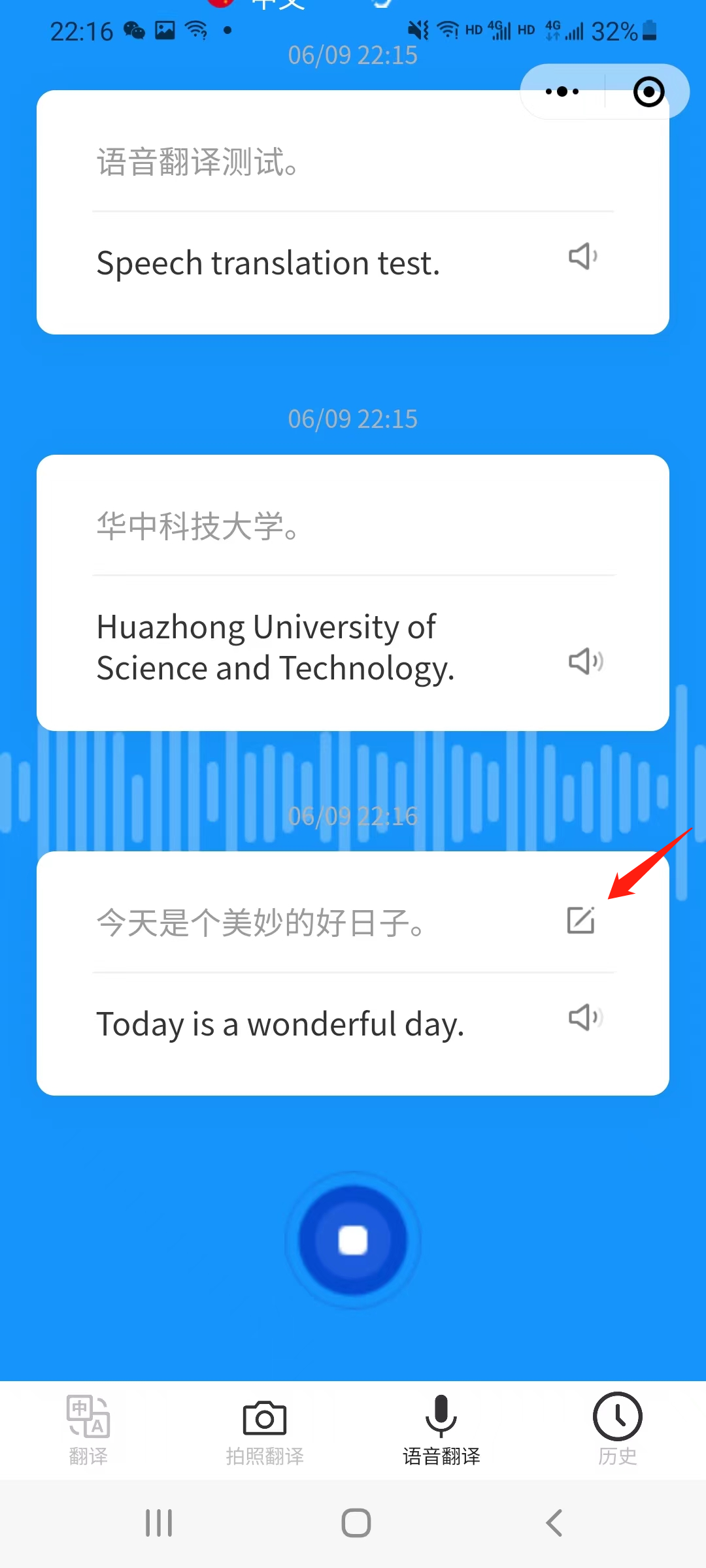
长按录音按钮,按钮样式改变,出现文字提示正在录音,翻译的结果会以卡片的形式保存在本地。
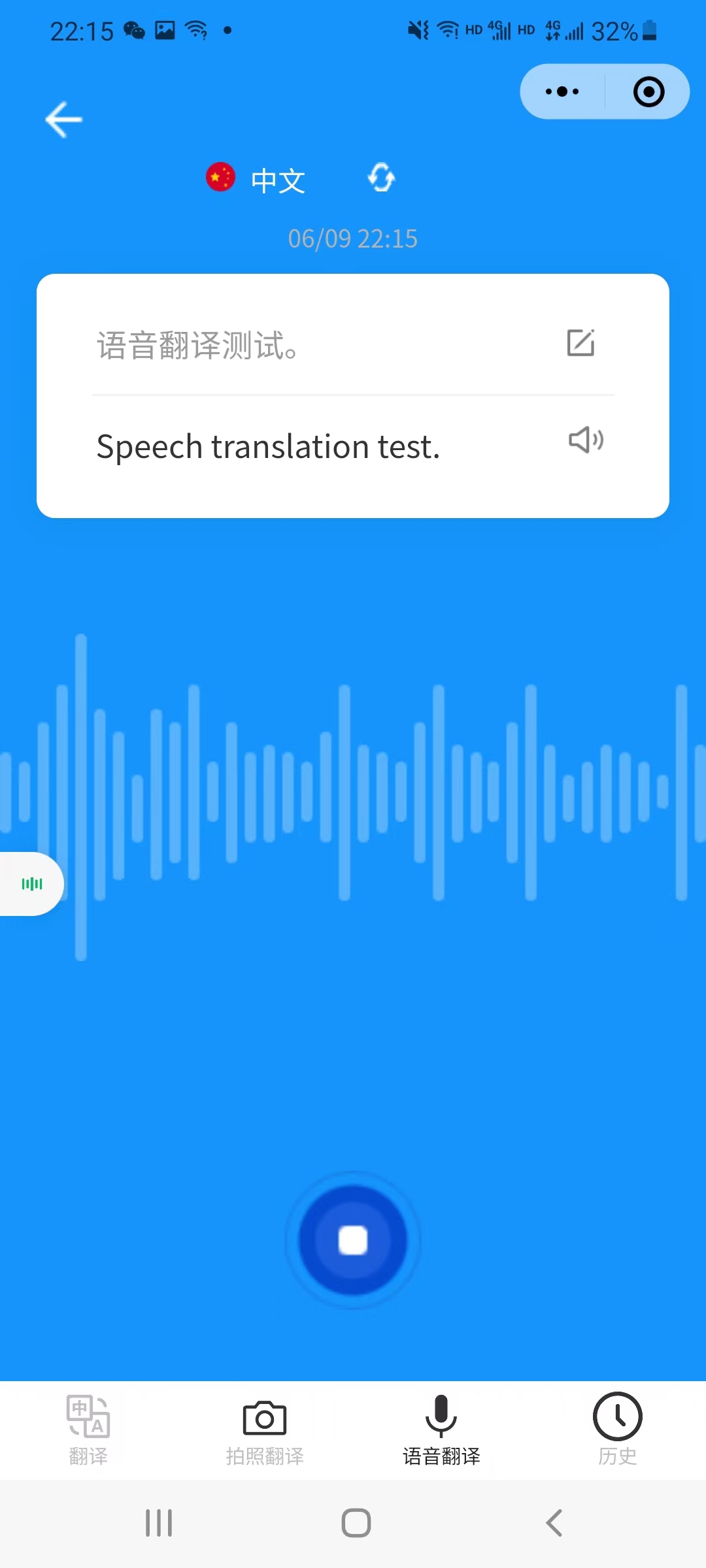
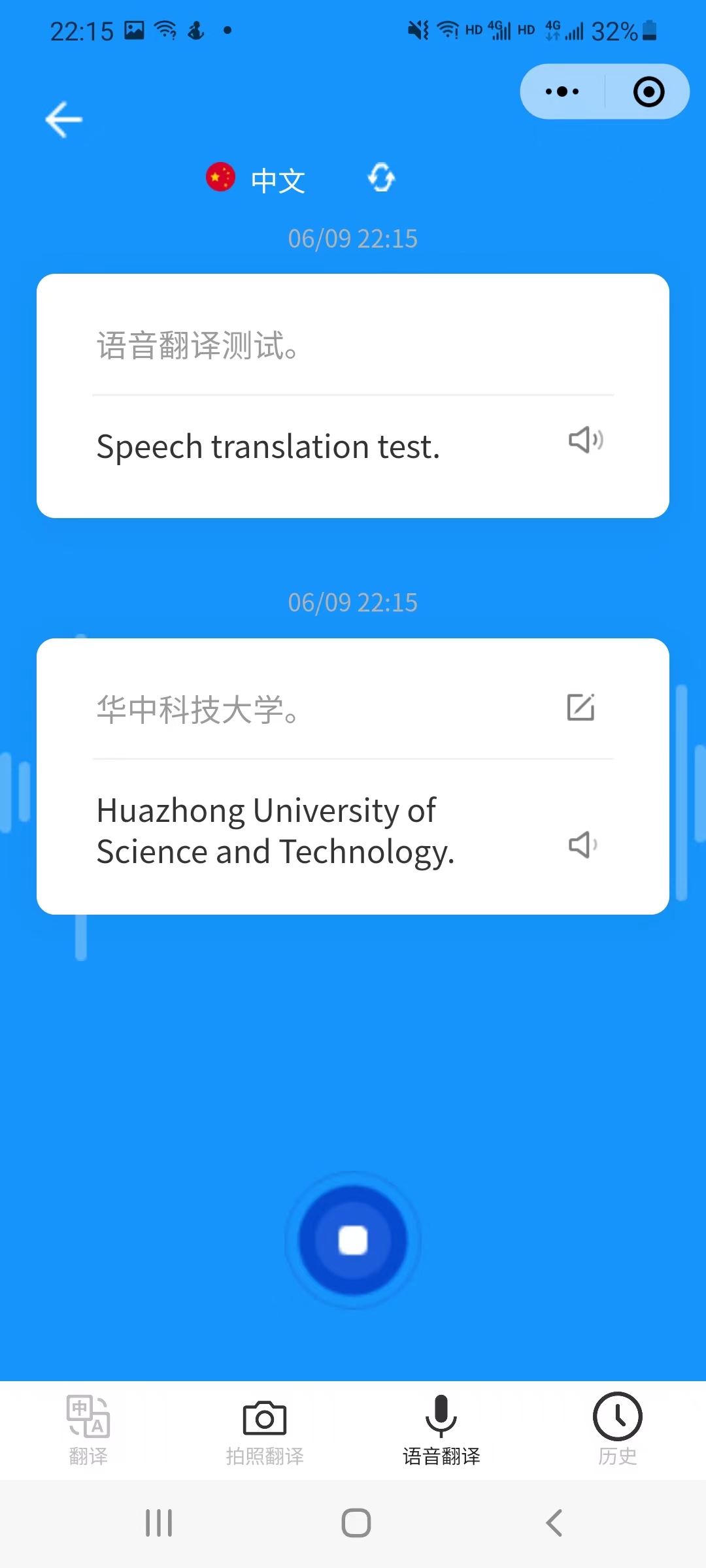
在卡片右侧对应两个组件,分别代表编辑文本和语音合成。
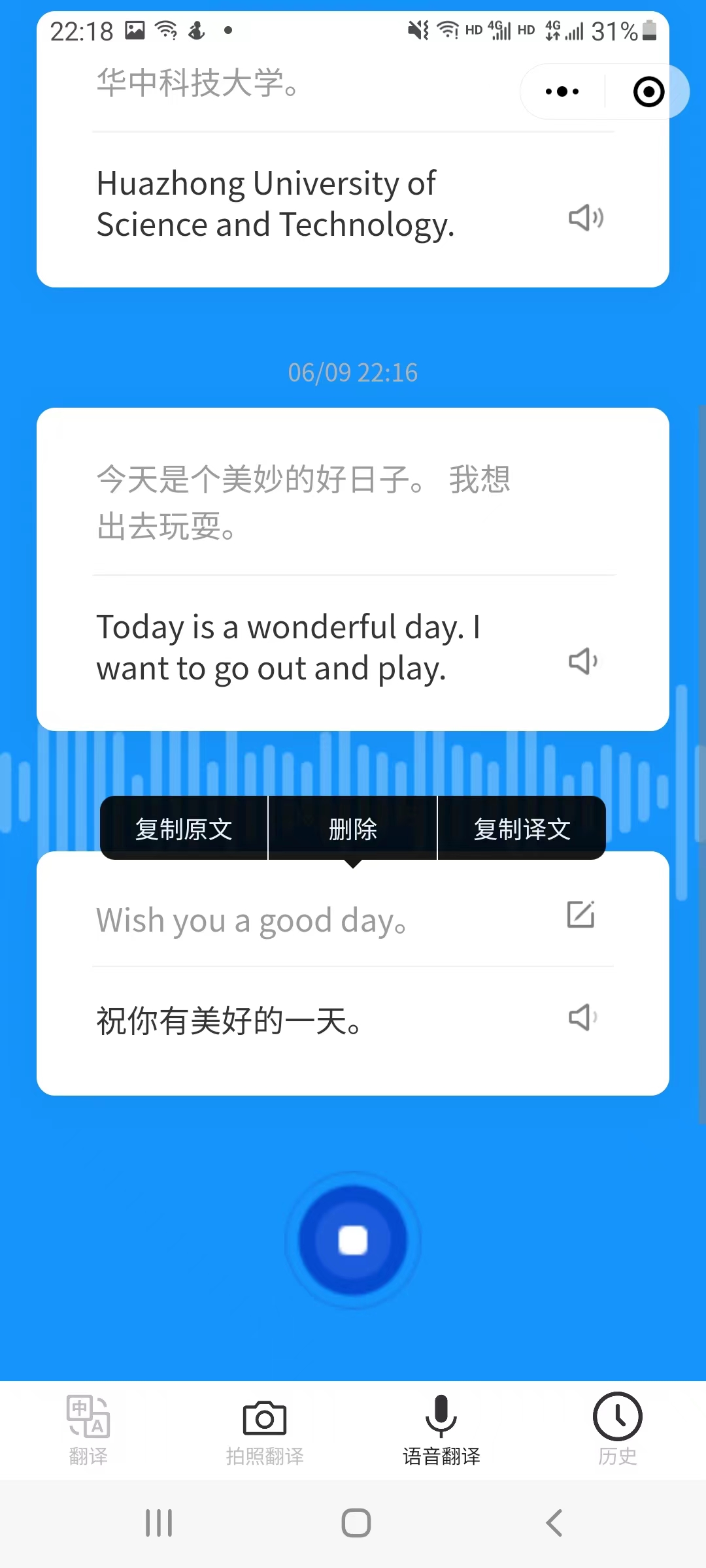
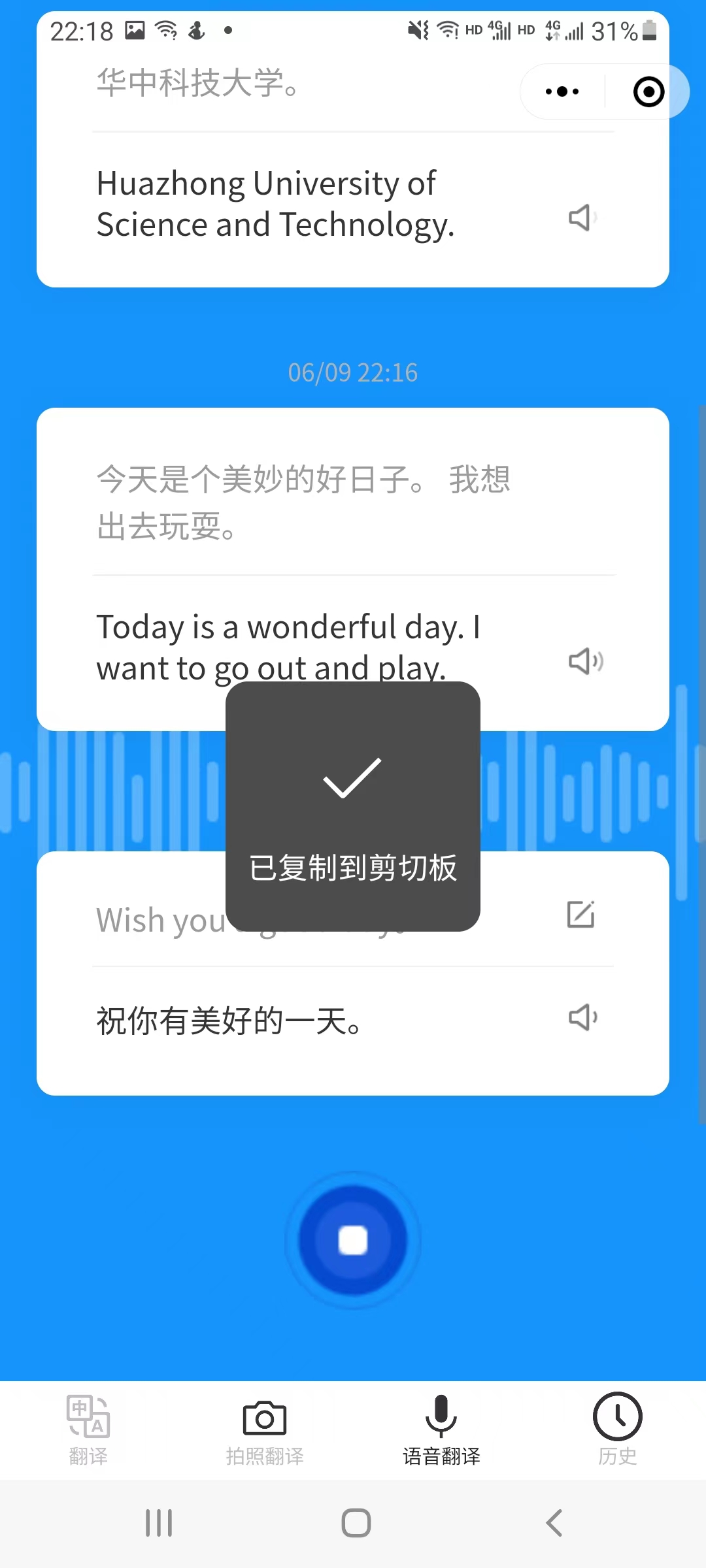
长按卡片出现弹窗,功能包括复制文本以及删除不用的卡片。
5.6 edit | 文本编辑界面
考虑到用户录音时可能会因为录音失误导致录入的文本有误,为避免用户重新录音的麻烦,允许编辑录音文本,为用户带来更好的体验。
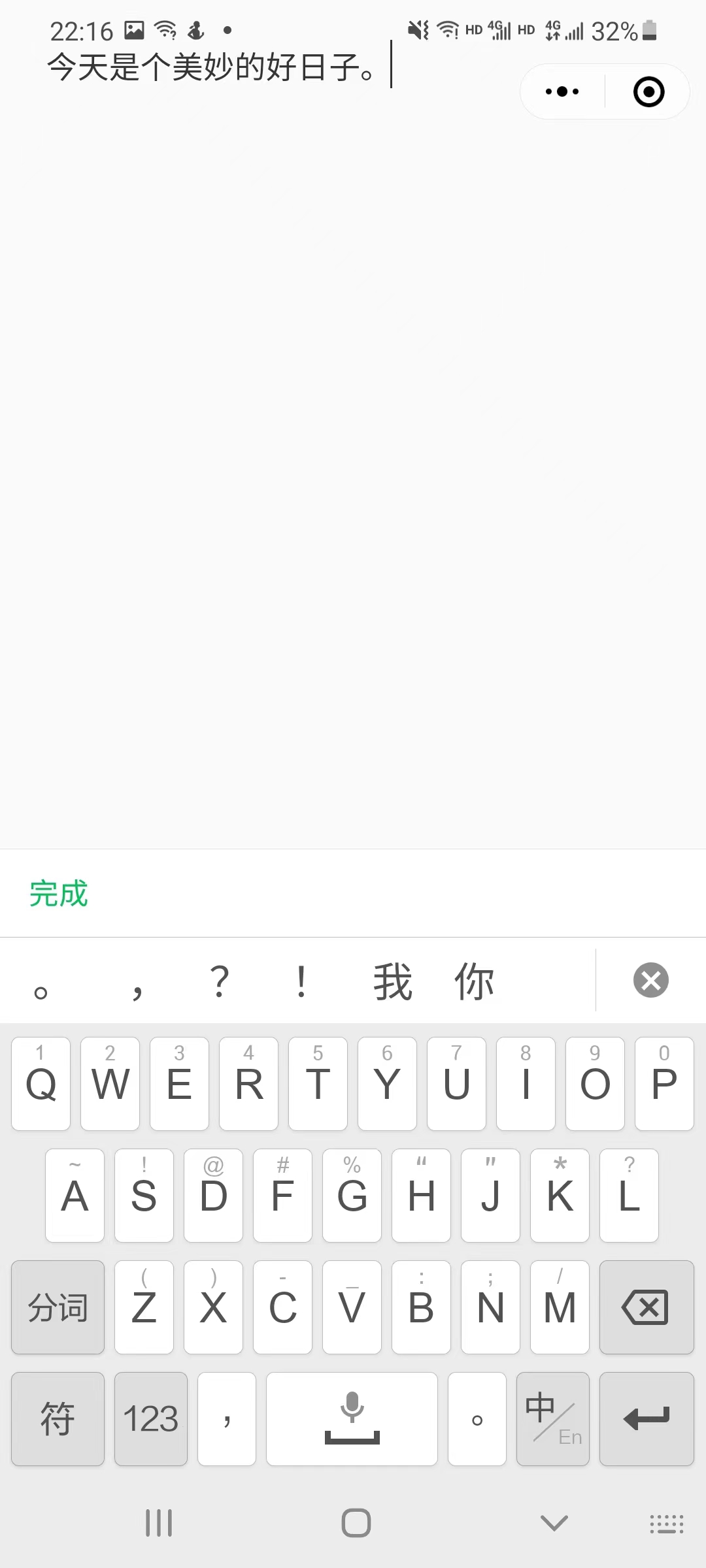
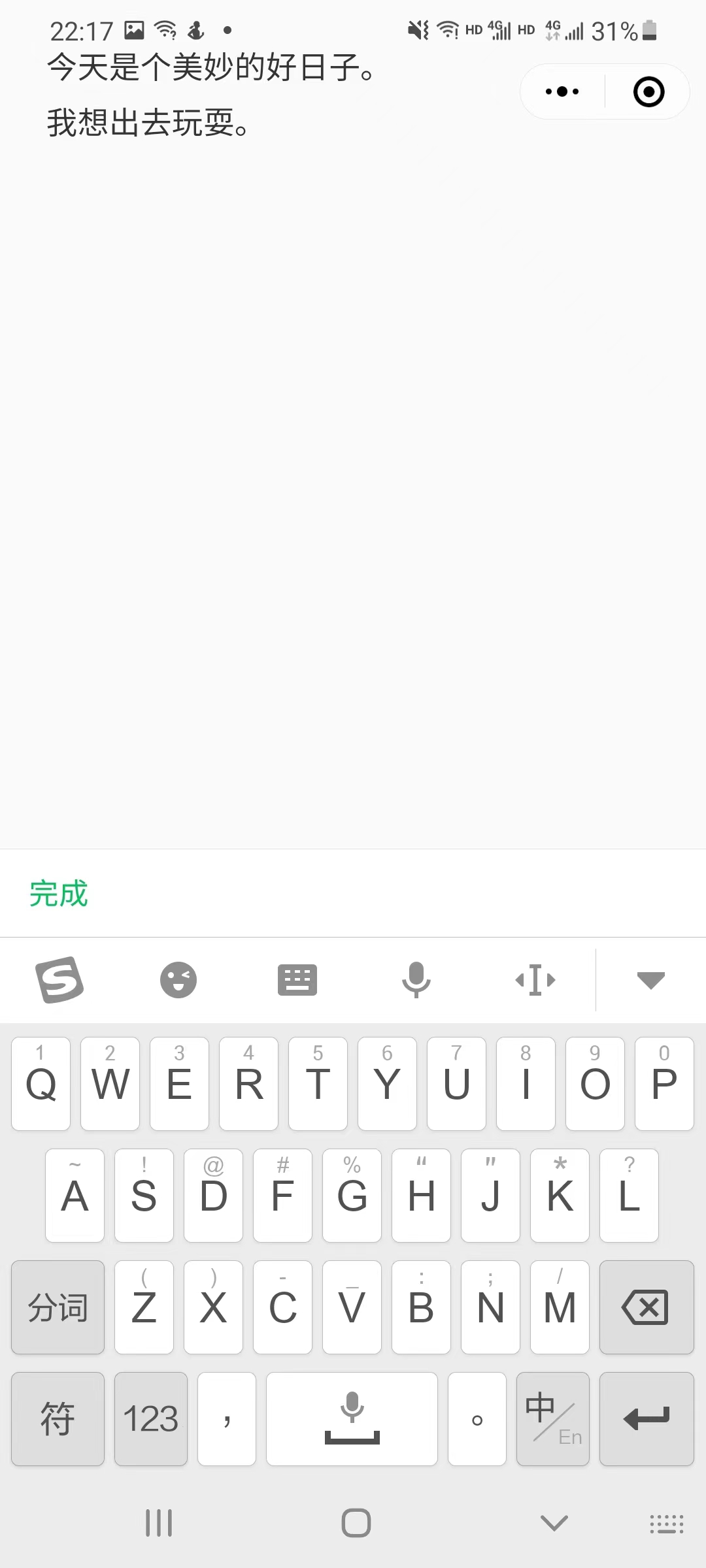
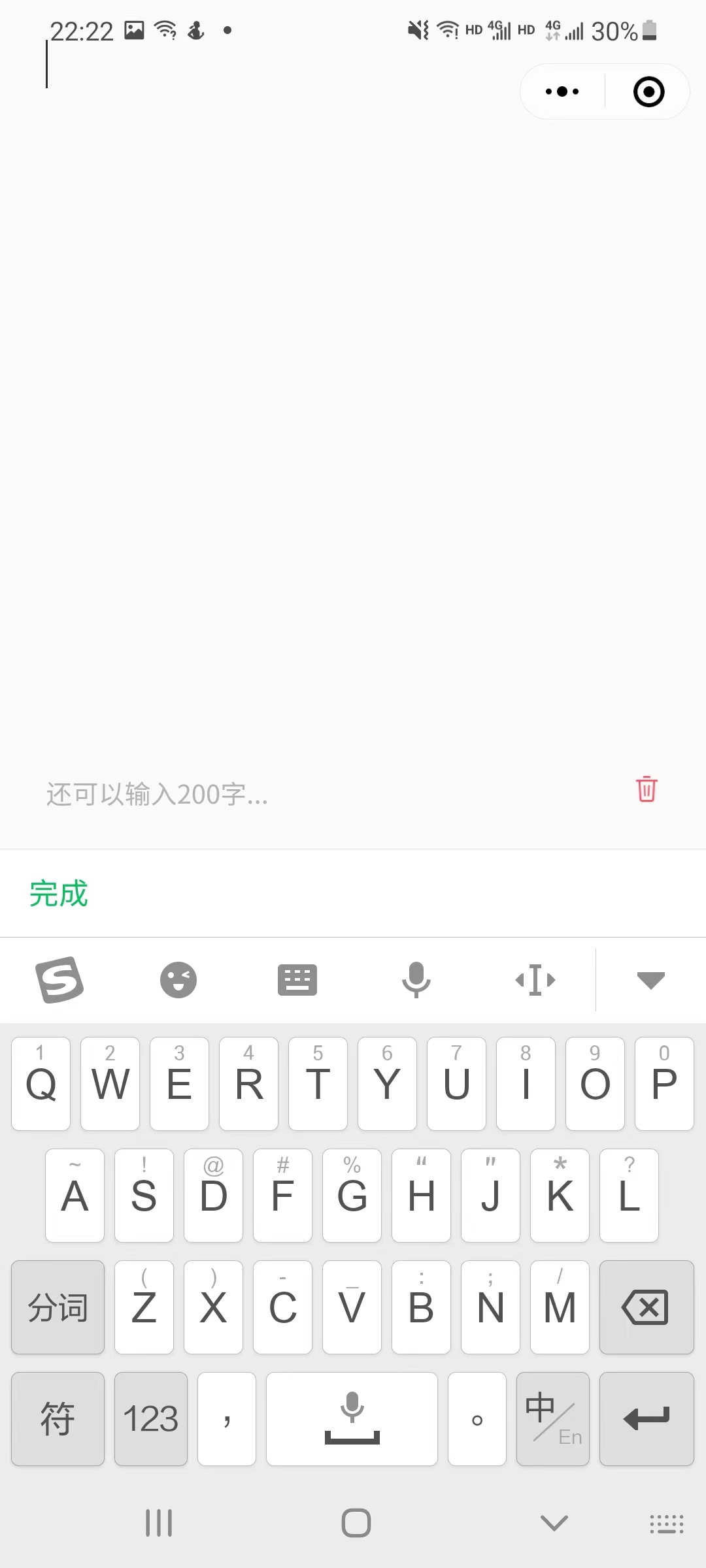
设置了最大输入文本限制,用户可以看到剩余可输入文字,点击清空按钮可以快速清除文字

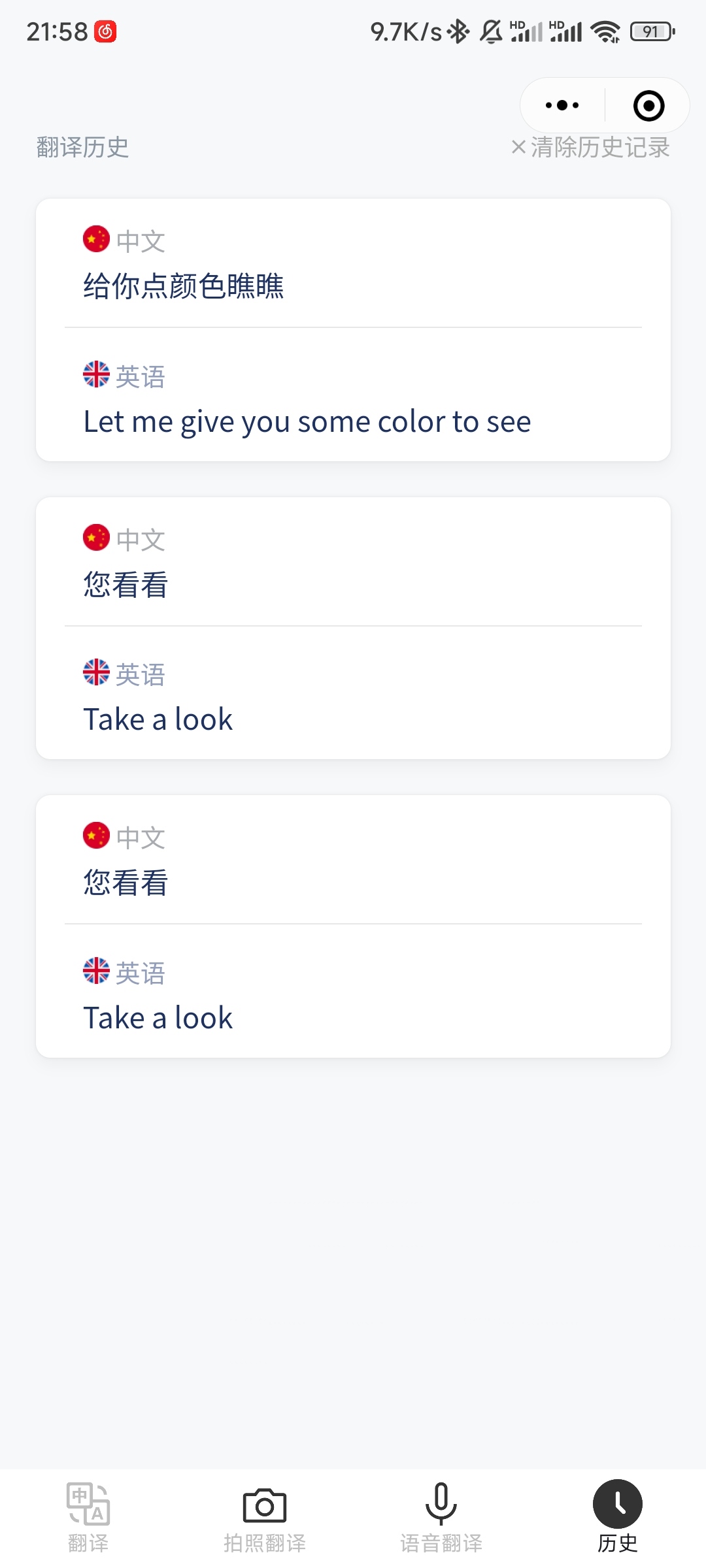
5.7 history | 翻译历史
在这个界面,用户可以查看使用小程序的翻译历史,点击对应的翻译历史可以跳转到主页查看翻译结果。
6. 总结
在这个课程设计项目中,我们的团队开发了一个名为TransWe的微信小程序。这是一个强大的机器翻译工具,它的核心功能是能够快速准确地翻译各种语言。但是,我们并没有止步于此,我们还集成了第三方OCR、语音识别和语音合成服务,这些功能的加入使得TransWe不仅仅是一个翻译工具,更是一个全方位的语言服务平台,为用户提供了更便捷、高效的翻译服务。
在这个过程中,我们深入了解了微信小程序的开发流程和特性。微信小程序的特性如页面跳转、图片上传、音频播放等,都被我们充分利用,以实现TransWe的各项功能。同时,我们也学习了如何利用第三方服务来增强小程序的功能性和用户体验。例如,我们利用OCR服务实现了图片中文本的识别,利用语音识别和语音合成服务实现了语音翻译功能,这些都大大提高了TransWe的用户体验。
在代码实现方面,我们遵循了良好的编程习惯。我们的代码结构清晰,每个函数、每个模块都有其明确的职责;我们的命名规范,变量名、函数名都能准确地反映其功能;我们的注释详细,每一段重要的代码都有相应的注释,方便后续的维护和修改。这些都是我们在软件工程课程中学到的重要知识,也是我们在实际开发过程中得到应用的地方。
然而,这个项目的开发过程并非一帆风顺。我们遇到了一些挑战,如API调用的问题、图片大小限制的问题等。但是,我们并没有因此而退缩,我们通过查阅文档、搜索解决方案、反复测试等方式,最终都成功地解决了这些问题。这个过程不仅锻炼了我们的问题解决能力,也让我们更加深入地理解了软件开发的实际过程。
总的来说,这个课程设计项目是一次非常宝贵的实践经验。它不仅提升了我们的编程技能,也锻炼了我们的问题解决能力。同时,看到自己的作品能够真正地帮助到用户,也是一种非常满足的感觉。我们深感,软件开发不仅仅是编写代码,更是解决问题,满足用户需求的过程。我们将带着这次的经验和教训,继续在软件工程的道路上探索和前进。
7. 理论课实验报告
下面是软件工程理论课的实验报告:重构实验,寻找代码中的坏味道。
一、实验目的、内容和要求
1.1 实验名称
- 重构实验
1.2 实验目的
理解重构在软件开发中的作用
熟悉常见的代码环味道和重构方法
1.3 实验内容和要求
阅读:Martin Fowler 《重构-改善既有代码的设计》
掌握你认为最常见的8种代码坏味道及其重构方法
从你过去写过的代码或Github等开源代码库上寻找这8种坏味道,并对代码进行重构;反对拷贝别人重构例子。
二、代码重构
2.1 重构1:神秘命名(Mysterious Name)
2.1.1 坏味道代码
1 | def func(a, b): |
这段代码来自我初学python时写的HelloWorld.py 文件,代码定义了一个函数,这个函数的输入是两个数a, b;输出是a + b。
2.1.2 坏味道说明
“神秘命名”是一种常见的坏味道,它指的是在代码中使用没有明确含义的变量、函数、类、模块等命名。这些命名往往缺乏清晰的语义和上下文,让其他开发人员难以理解代码的意图和目的。这可能导致代码可读性和可维护性的下降,并且增加了调试和重构代码的难度。
神秘命名的危害在于它会导致代码难以理解和维护。当其他开发人员需要在代码中添加新的功能或者修改代码时,他们可能需要花费更多的时间来理解这些命名的含义和作用。这可能导致开发时间的延长和错误的引入,从而降低了代码质量和开发效率。
2.1.3 重构方法
为了解决神秘命名的问题,可以采取以下重构方法:
- 更改命名:将神秘的命名更改为更有意义和描述性的名称,使代码更易于理解和维护。
- 引入注释:在代码中添加注释可以帮助其他开发人员理解变量、函数、类等的含义和用途,特别是在一些情况下,无法通过名称清楚地表达其意图时。
- 优化命名规范:制定良好的命名规范并将其应用于整个代码库可以减少神秘命名的发生。在规范中,定义变量、函数、类、模块等的命名规则,并尽可能遵循这些规则。
2.1.4 重构后代码
1 | def add(a, b): # a, b represent the two addend number |
2.2 重构2:重复代码(Duplicated Code)
2.2.1 坏味道代码
1 | // cow movement |
代码来源:我自己写的一道算法题USACO2.4两只塔姆沃斯牛 The Tamworth Two,这段代码的作用是控制农夫和牛在地图中方向的移动。
2.2.2 坏味道说明
“重复代码”是一种常见的坏味道,它指的是代码中存在多个相同或非常相似的代码片段。这些重复的代码可能存在于同一个文件、不同的文件或不同的代码库中,但它们执行的功能相同或者非常相似。
重复代码的危害在于它会导致代码冗余和维护困难。如果存在多个相同或相似的代码片段,每次需要修改功能时,必须修改所有重复的代码。这会增加代码的维护难度,并且可能导致错误的引入。此外,重复的代码还会占用更多的内存和磁盘空间,从而导致代码库变得更加庞大和不易维护。
2.2.3 重构方法
为了解决重复代码的问题,我们可以采取以下重构方法:
- 提取方法:将重复的代码段提取到一个独立的方法中,并在需要时调用该方法。这可以减少重复代码并提高代码的可重用性。
- 抽象公共方法:如果有多个代码段具有相同的结构,可以将它们抽象为一个通用方法,并在需要时使用。这可以减少重复代码的数量并提高代码的可维护性。
2.2.4 重构后代码
1 | void move(object& obj) |
2.3 重构3:过长函数(Long Function)
2.3.1 坏味道代码
1 |
|
这段代码是我利用C语言实现的高精度乘法,可以对两个$10^{20}$ 的超级大整数相乘,采用数组模拟乘法的相乘与进位,思路是消耗空间换取时间。
2.3.2 坏味道说明
过长函数是指代码中某个函数过于冗长复杂,超过应有的长度限制,使得代码难以阅读、理解和维护。这种坏味道的存在会导致代码质量下降、可读性差、出错率高等问题,并且难以重用或调试。比如这段代码中一连串的for代码根本让人不知所云。
2.3.3 重构方法
对于过长函数的重构,考虑以下思路:
- 拆分函数:将一个函数按照不同的职责或功能进行拆分,形成多个小函数,每个小函数只负责一项具体的工作,这样可以降低单个函数的复杂度和长度。
- 提取方法:将函数中的某些独立操作提取为新的方法,以减少代码重复和提高重用性。
- 优化参数列表:如果函数参数列表过长,可以考虑将其中的相关参数放置在同一个对象中,以简化函数的参数列表并提高代码可读性。
- 使用注释:对于一些长函数,可以使用注释来标识代码的不同执行分支或处理步骤,以提高代码可读性。
2.3.4 重构后代码
1 |
|
2.4 重构4:过长参数列表(Long Parameter List)
2.4.1 坏味道代码
1 | def calculate_score(name, age, gender, height, weight, math_score, english_score, chinese_score): |
该代码来自我在学习python的面向对象的概念是完成的学生成绩管理系统,这段代码的作用是根据学生的性别,身高,体重,成绩等数据计算学生的分数并进行返回。
2.4.2 坏味道说明
“过长参数列表”是指函数或方法的参数数量过多或者参数类型过于复杂,导致函数声明或调用代码难以阅读和理解。这种坏味道可能导致代码的可维护性和可读性降低,同时也会增加代码的复杂度和错误的引入。
过长参数列表的危害在于它会导致代码难以理解和维护。当其他开发人员需要在代码中添加新的功能或者修改代码时,他们可能需要花费更多的时间来理解参数的作用和顺序。这可能导致开发时间的延长和错误的引入,从而降低了代码质量和开发效率。
2.4.3 重构方法
为了解决过长参数列表的问题,我们可以采取以下重构方法:
- 重构为对象:将参数封装成一个对象,并将该对象作为参数传递给函数。这样可以减少函数的参数数量,提高代码的可读性和可维护性。
- 使用默认值:对于一些不是必须的参数,可以设置默认值来避免在调用函数时传递参数。
- 重构为多个函数:如果一个函数的参数过多,可以考虑将其拆分成多个较小的函数,每个函数只需要少量的参数。
- 重构为参数对象:将多个参数封装成一个参数对象,并在函数声明中只传递一个参数对象。这样可以减少函数的参数数量,提高代码的可读性和可维护性。
通过上述重构方法,我们可以减少函数的参数数量,提高代码的可读性和可维护性,避免过长参数列表带来的问题。
2.4.4 重构后代码
1 | class Student: |
2.5 重构5: 全局数据(Global Data)
2.5.1 坏味道代码
1 |
|
2.5.2 坏味道说明
全局数据是指在整个程序中可被访问的数据,它们可以是全局变量、静态变量或常量等。这种坏味道的存在会导致代码的耦合度高、可维护性差、扩展性低等问题。
全局数据的危害包括:
- 导致代码依赖复杂:由于全局数据可以被整个程序的任何部分引用和修改,因此当多个模块之间共享同一个全局数据时,代码的依赖关系变得非常复杂,使得代码难以理解和维护。
- 难以进行单元测试:全局数据的存在会影响到模块的独立性,使得模块的单元测试变得困难,需要考虑全局数据的状态和影响范围。
- 安全性问题:全局数据容易被不同模块同时访问和修改,这可能导致数据的竞争条件和安全漏洞。
2.5.3 重构方法
针对全局数据的坏味道,考虑以下重构方法:将全局数据转换为局部数据:将全局变量转化为函数参数或返回值,将静态变量转化为函数内的局部变量,这样可以减少对全局数据的依赖,提高代码的独立性和可维护性。
2.5.4 重构后代码
1 |
|
2.6 可变数据
2.6.1 坏味道代码
1 |
|
这段代码是我自己写的快速幂,通过二分的思想将求取$a^b$的算法从O(n)的复杂度降低至O(log n),在处理需要大量幂运算的程序中大大提高了程序的运行效率。
2.6.2 坏味道说明
可变数据是指在函数中修改了参数的值,导致代码的可读性差、维护成本高、易出现意外错误。重构的方法是尽可能避免修改参数的值,可以采用复制、封装成类等方式避免修改参数的值。
2.6.3 重构方法
要消除可变数据的坏味道,可以使用以下重构方法:将可变数据的修改范围限制在单个函数内部。通过定义局部变量,可以确保变量的生命周期仅限于该函数,并且不会泄露到程序的其他部分。
2.6.4 重构后代码
1 |
|
2.7 重构7: 发散式变化(Divergent Change)
2.7.1 坏味道代码
1 | class Rectangle: |
这段代码是我在学习python面向对象——继承的时候写的代码,代码定义了长方形类和正方形类,其中get_area函数用来求对应对象的面积。
2.7.2 坏味道说明
发散式变化是指修改一个类需要修改多个地方的代码,导致代码的可维护性差、扩展性差。这种坏味道的存在会导致代码的耦合度高、可维护性差、扩展性低等问题。
2.7.3 重构方法
对于发散式变化的重构,可以考虑以下思路:
- 应用面向对象设计原则:例如单一职责原则(SRP)和开放封闭原则(OCP),确保代码的职责分明,易于扩展和维护。
- 重构共享代码:将不同职责之间共享的代码提取出来,形成通用的类或模块,以降低代码的冗余度。
2.7.4 重构后代码
1 | class Rectangle: |
2.8 数据泥团(Data Clumps)
2.8.1 坏味道代码
1 | int calculate_total_cost(int num_items, float price_per_item, float tax_rate) |
2.8.2 坏味道说明
数据泥团指的是一组数据在代码中反复出现,这些数据之间存在某种联系或者依赖关系,但是却没有被单独封装起来。这样的代码会导致代码重复和可维护性下降。 在上述代码中,num_items、price_per_item、tax_rate、subtotal、tax_amount等数据反复出现,这些数据之间存在联系,但是没有被封装起来,导致代码重复,难以维护。
2.8.3 重构方法
重构思路是将这些数据封装起来,形成一个独立的数据结构。这个数据结构可以是一个类、一个结构体、一个数组等等,具体形式取决于具体场景。 对于上述代码,我们可以将num_items、price_per_item、tax_rate封装成一个结构体,这样,我们就将相关的数据封装成一个Order结构体,并将计算subtotal、tax_amount的逻辑封装到了相应的函数中,代码变得更清晰、易于维护。
2.8.4 重构后代码
1 | typedef struct { |
三、实验总结
通过这次重构实验,我深刻理解了重构在软件开发中的重要性。重构不仅可以改善代码的设计,提高代码的可读性和可维护性,还可以使代码更加清晰、简洁、易于扩展和修改。在重构过程中,我们需要熟悉常见的代码坏味道和重构方法,只有在深入理解和掌握了这些概念和技巧之后,才能正确地进行代码重构。
在本次实验中,我阅读了Martin Fowler的《重构-改善既有代码的设计》,并掌握了8种常见的代码坏味道及其重构方法。对于每一种坏味道,我都学会了相应的重构方法,例如,对于长方法,可以采取函数分解、函数组合以及提炼函数的方式进行重构;对于大类,可以采取提炼子类、提炼接口、提炼模块、提炼聚集以及提炼超类的方式进行重构。
在完成实验要求时,我选择了从自己过去写过的代码和Github等开源代码库中寻找这8种常见的坏味道,并对代码进行重构。在实践中,我深刻感受到了代码重构的必要性和难度。在重构过程中,需要仔细分析每一行代码以及代码之间的关系,考虑如何改进代码的结构和逻辑。同时还需要避免破坏代码的原有功能。
总之,通过这次实验,我对代码重构有了更深入的理解和认识。我认识到,在日后的编程工作中,我需要注意以下几个方面:首先,我的代码应该尽可能地简洁、可读、易于维护;其次,我应该时刻关注代码中存在的坏味道,及时采取相应的重构方法优化代码;最后,我需要不断学习和掌握新的技术和工具,以便更加高效和优雅地完成编程任务。
 wechat
wechat alipay
alipay





